By Moritz Mueller-Freitag, Eleven Strategy.
tietojen” kohtuuttomasta tehokkuudesta ” koneoppimissovelluksissa on keskusteltu laajasti vuosien varrella (Katso tästä, tästä ja tästä). On myös esitetty, että monia suuria läpimurtoja tekoälyn alalla eivät ole rajoittaneet algoritmiset edistysaskeleet vaan korkealaatuisten tietokokonaisuuksien saatavuus (Katso tästä). Näiden keskustelujen yhteisenä lankana on, että data on elintärkeä osa huipputeknistä koneoppimista.
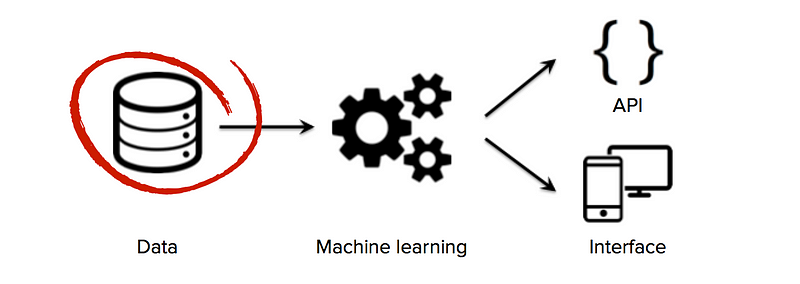
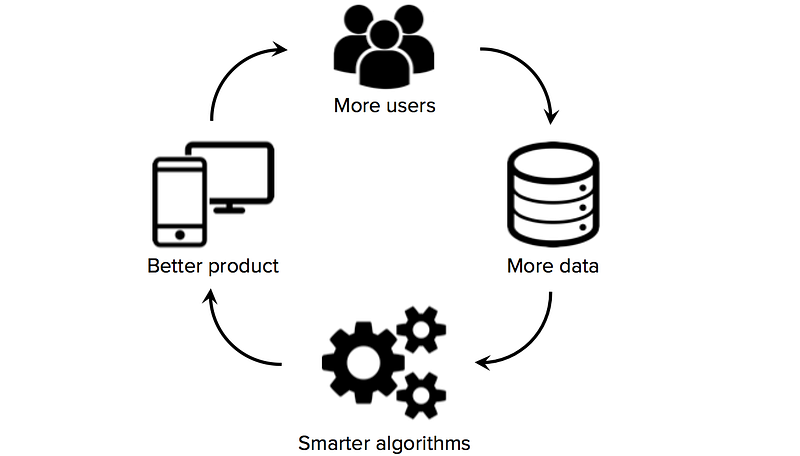
korkealaatuisen koulutustietojen saatavuus on ratkaisevan tärkeää startupeille, jotka käyttävät koneoppimista liiketoimintansa ydinteknologiana. Vaikka monet algoritmit ja ohjelmistotyökalut ovat avoimia ja jaettuja tutkimusyhteisössä, hyvät tietokokonaisuudet ovat yleensä omia ja vaikeasti rakennettavia. Suuren, verkkotunnuskohtaisen tietokokonaisuuden omistamisesta voi siis tulla merkittävä kilpailuedun lähde, varsinkin jos startupit voivat käynnistää dataverkon vaikutukset (tilanne, jossa enemmän käyttäjiä → enemmän dataa → älykkäämpiä algoritmeja → parempi tuote → enemmän käyttäjiä).
näin ollen yksi tärkeimmistä strategisista päätöksistä, joita koneoppimisen aloittavien on tehtävä, on rakentaa laadukkaita tietokokonaisuuksia oppimisalgoritmien kouluttamiseksi. Valitettavasti startup-yrityksillä on usein alussa vain vähän tai ei lainkaan merkittyjä tietoja, mikä estää perustajia edistymästä merkittävästi datapohjaisen tuotteen rakentamisessa. Tiedonhankintastrategioita kannattaakin tutkia alusta alkaen, ennen datatieteellisen tiimin palkkaamista tai kalliin perusinfrastruktuurin rakentamista.
startupit voivat voittaa tiedonhankinnan kylmäkäynnistysongelman monin tavoin. Datastrategian/lähteen valinta kulkee yleensä käsi kädessä liiketoimintamallin valinnan, startupin painopisteen (kuluttaja tai yritys, horisontaalinen tai vertikaalinen jne.) ja rahoitustilanne. Vaikka seuraava strategialuettelo ei ole tyhjentävä eikä toisiaan poissulkeva, se antaa käsityksen käytettävissä olevien lähestymistapojen laajasta valikoimasta.
strategia #1: manuaalinen työ
hyvän Oman aineiston rakentaminen tyhjästä tarkoittaa lähes aina sitä, että tiedonhankintaan panostetaan paljon etukäteen, inhimillisesti ja että tehdään manuaalisia tehtäviä, jotka eivät ole mittakaavaetuja. Esimerkkejä startupeista, jotka ovat käyttäneet alussa raakaa voimaa, on runsaasti. Esimerkiksi monet chatbot-startupit työllistävät inhimillisiä ”TEKOÄLYKOULUTTAJIA”, jotka luovat tai todentavat virtuaaliagenttiensa tekemiä ennustuksia manuaalisesti (vaihtelevalla menestyksellä ja suurella työntekijöiden vaihtuvuudella). Jopa teknologiajätit turvautuvat tähän strategiaan: kaikki Facebook M: n vastaukset käydään läpi ja editoidaan urakoitsijoiden voimin.

raa ’ an voiman käyttäminen datapisteiden manuaaliseen merkitsemiseen voi olla onnistunut strategia, kunhan tietoverkon vaikutukset alkavat jossain vaiheessa vaikuttaa niin, että ihmiset eivät enää skaalaudu yhtä nopeasti asiakaskunnan kanssa. Heti kun tekoälyjärjestelmä paranee tarpeeksi nopeasti, määrittelemättömät poikkeamat vähenevät ja manuaalista merkintää tekevien ihmisten määrä voidaan vähentää tai pitää vakiona.
mielenkiintoinen: enemmän tai vähemmän jokainen koneoppimisen startup
esimerkit:
- monet chatbot-startupit (mm. Magic, GoButler, x.ai ja Clara)
- MetaMind (käsin kerätty ja merkitty tietokokonaisuus elintarvikeluokitusta varten)
- Rakennustutka (työntekijät / harjoittelijat merkitsevät käsin kuvia rakennuksista)
strategia #2: rajaa verkkotunnus
useimmat startupit yrittävät kerätä dataa suoraan käyttäjiltä. Haasteena on saada varhaiset omaksujat käyttämään tuotetta ennen kuin koneoppimisen hyödyt tulevat täysin esiin (koska dataa tarvitaan ylipäätään algoritmien kouluttamiseen ja hienosäätöön). Yksi tapa kiertää tämä catch-22 on rajusti kaventaa ongelma-aluetta (ja laajentaa soveltamisalaa myöhemmin tarvittaessa). Chris Dixon sanookin: ”tarvitsemasi tiedon määrä on suhteessa sen ongelman laajuuteen, jota yrität ratkaista.”
hyviä esimerkkejä kapean verkkotunnuksen hyödyistä ovat jälleen chatbotit. Tämän segmentin startupit voivat valita kahden go-to-market-strategian väliltä: ne voivat rakentaa horisontaalisia avustajia — botteja, jotka voivat auttaa hyvin monissa kysymyksissä ja välittömissä pyynnöissä (esimerkkeinä viv,Magic, Awesome, Maluuba ja Jam). Tai he voivat luoda vertikaalisia avustajia-botteja, jotka yrittävät suorittaa yhden tietyn, hyvin määritellyn työn erittäin hyvin (esimerkkejä ovat x.ai, Clara, DigitalGenius, Kasisto, Meekan – and more recentlyGoButler/Angel. ai). Vaikka molemmat lähestymistavat ovat päteviä, tiedonkeruu on huomattavasti helpompaa startup-yrityksille, jotka käsittelevät suljettujen verkkotunnusten ongelmia.
mielenkiintoinen: vertikaalisesti integroituneet yritykset
esimerkit:
- korkeasti erikoistuneet pysty chatbotit (kuten x.ai, Clara tai GoButler)
- syvä genomiikka (käyttää syväoppimista geenivarianttien luokitteluun/tulkintaan)
- kvantifioitu iho (käyttää asiakkaan selfieitä ihmisen ihon analysointiin)
strategia #3: Joukkoistaminen / ulkoistaminen
sen sijaan, että päteviä työntekijöitä (tai harjoittelijoita) käytettäisiin manuaalisesti tietojen keräämiseen tai merkitsemiseen, startupit voivat myös joukkoistaa prosessin. Alustat, kuten Amazon Mechanical Turk tai CrowdFlower, tarjoavat tavan siivota sotkuista ja puutteellista tietoa käyttämällä miljoonien ihmisten online-työvoimaa. Esimerkiksi VocalIQ (jonka Apple osti vuonna 2015) käytti Amazonin Mechanical Turkia syöttääkseen digitaaliselle avustajalleen tuhansia käyttäjien kyselyjä. Työntekijöitä voidaan myös ulkoistaa palkkaamalla muita itsenäisiä urakoitsijoita (kuten byclara tai Facebook M). Tämän lähestymistavan käytön edellytyksenä on, että tehtävä voidaan selittää selkeästi eikä se ole liian pitkä/tylsä.

toinen taktiikka on yllyttää yleisöä antamaan tietoja vapaaehtoisesti. Esimerkki on Snips, pariisilainen tekoälyn startup, joka käyttää tätä lähestymistapaa saadakseen käsiinsä tietyntyyppisiä tietoja (vahvistussähköpostit ravintoloille, hotelleille ja lentoyhtiöille). Kuten muutkin startupit, Snips käyttää pelillistä järjestelmää, jossa käyttäjät sijoittuvat tulostaululle.
mielenkiintoinen: Käyttö tapaukset, joissa laadunvalvonta on helposti toteutettavissa
esimerkkejä:
- DeepMind, Maluuba, AlchemyAPI ja monet muut (KS. täältä)
- VocalIQ (käytti mekaanista turkkilaista opettaakseen ohjelmaansa, miten ihmiset puhuvat)
- Snips (pyytää ihmisiä antamaan vapaasti tietoa tutkimusta varten))
strategia #4: User-in-the-loop
joukkoistamisstrategia, joka ansaitsee oman kategoriansa, on user-in-the-loop.Tähän lähestymistapaan kuuluu sellaisten tuotteiden suunnittelu, jotka tarjoavat käyttäjille oikeat kannustimet tietojen palauttamiseen järjestelmään. Kaksi klassista esimerkkiä yrityksistä,jotka ovat käyttäneet tätä lähestymistapaa monissa tuotteissaan, ovat Google (automaattinen täydennys haussa, Google Translate, roskapostisuodattimet jne.) ja Facebook(käyttäjät tägäävät kavereitaan valokuviin). Käyttäjät ovat usein tietämättömiä siitä, että he antavat näille yrityksille merkittyjä tietoja ilmaiseksi.
monet koneoppimistilan startupit ovat ammentaneet inspiraatiota Googlelta ja Facebookilta luomalla tuotteita, joissa on vikasietoinen UX, joka nimenomaan kannustaa käyttäjiä korjaamaan koneen virheitä. Erityisen merkittäviä ovat arere ja Duolingo (molemmat Luis von Ahnin perustamia). Muita esimerkkejä ovat Unbabel, Wit.ai ja Mapillary.
mielenkiintoista: Kuluttajakeskeiset startupit, joissa on jatkuva käyttäjien vuorovaikutus
esimerkkejä:
- Unbabel (community translators correct machine-generated translations)
- Wit.ai (tarjotaan dashboard/API käyttäjille käännösvirheiden korjaamiseksi)
- Mapillary (käyttäjät voivat korjata koneellisesti luodun liikennemerkin tunnistuksen)
strategia #5: Sivubisnes
computer vision-startupien keskuudessa erityisen suosittu strategia on tarjota ilmainen, verkkotunnuskohtainen mobiilisovellus, joka on suunnattu kuluttajille. Clarifai, HyperVerge ja Madbits (osti Twitter vuonna 2014) ovat kaikki noudattaneet tätä strategiaa tarjoamalla valokuvasovelluksia, jotka keräävät lisää kuvadataa ydinliiketoimintaansa.
tämä strategia ei ole täysin riskitön (sovelluksen menestyksekäs kehittäminen ja edistäminen maksaa aikaa ja rahaa). Startupien on myös huolehdittava siitä, että ne luovat riittävän vahvan käyttötapauksen, joka pakottaa käyttäjät luopumaan datastaan, vaikka palvelusta puuttuisikin alussa dataverkkovaikutusten hyödyt.
mielenkiintoinen: yritysten startupit/horisontaaliset alustat
esimerkit:
- Clarifai (Forevery, photo discovery app)
- HyperVerge (Silver, photo organization app)
- Madbits (Momentsia, photo collage app)