door Moritz Mueller-Freitag, Eleven Strategy.
de “onredelijke effectiviteit” van gegevens voor toepassingen voor machine-leren is in de loop der jaren uitgebreid besproken (zie hier, hier en hier). Er is ook gesuggereerd dat veel belangrijke doorbraken op het gebied van kunstmatige intelligentie niet werden beperkt door algoritmische vooruitgang, maar door de beschikbaarheid van hoogwaardige datasets (zie hier). De rode draad door deze discussies is dat data is een essentieel onderdeel in het doen van state-of-the-art machine learning.
toegang tot hoogwaardige trainingsgegevens is van cruciaal belang voor starters die machine learning als de kerntechnologie van hun bedrijf gebruiken. Hoewel veel algoritmen en softwaretools open source zijn en gedeeld worden door de onderzoeksgemeenschap, zijn goede datasets meestal propriëtair en moeilijk te bouwen. Het bezitten van een grote, domeinspecifieke dataset kan daarom een belangrijke bron van concurrentievoordeel worden, vooral als startups datanetwerk-effecten kunnen versnellen (een situatie waarin meer gebruikers → meer gegevens → slimmere algoritmen → beter product → meer gebruikers).
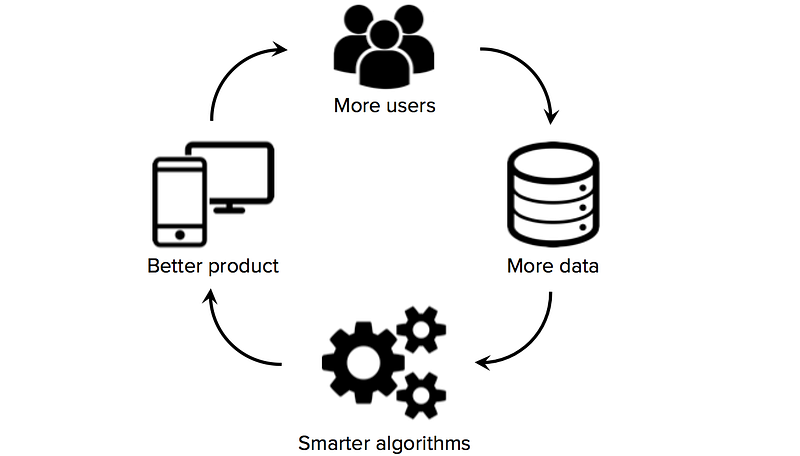
daarom is een van de belangrijkste strategische beslissingen die startups voor machine learning moeten maken, hoe ze hoogwaardige datasets moeten bouwen om hun leeralgoritmen te trainen. Helaas hebben startups in het begin vaak beperkte of geen gelabelde gegevens, een situatie die oprichters belet aanzienlijke vooruitgang te boeken bij het bouwen van een data-driven product. Het is daarom de moeite waard om vanaf het begin data-acquisitiestrategieën te onderzoeken, alvorens het data science-team aan te nemen of een kostbare kerninfrastructuur op te bouwen.
Startups kunnen het cold start probleem van data-acquisitie op tal van manieren oplossen. De keuze van de data strategie / bron gaat meestal hand-in-hand met de keuze van het bedrijfsmodel, de focus van een startup (consument of onderneming, horizontaal of verticaal, enz.) en de financieringssituatie. De onderstaande lijst van strategieën is weliswaar niet uitputtend, noch sluiten zij elkaar uit, maar geeft een idee van de brede waaier van beschikbare benaderingen.
strategie # 1: handmatig werk
een goede eigen dataset vanaf het begin opbouwen betekent bijna altijd dat er veel menselijke inspanningen moeten worden gedaan om gegevens te verzamelen en handmatige taken uit te voeren die niet schaalbaar zijn. Voorbeelden van startups die brute kracht hebben gebruikt in het begin zijn er in overvloed. Bijvoorbeeld, veel chatbot startups in dienst menselijke “AI trainers” die handmatig te maken of te controleren de voorspellingen van hun virtuele agenten maken (met wisselend succes en een hoog personeelsverloop). Zelfs de tech reuzen toevlucht tot deze strategie: alle reacties van Facebook M worden beoordeeld en bewerkt door een team van aannemers.

het gebruik van brute kracht om datapunten handmatig te labelen kan een succesvolle strategie zijn zolang de effecten van het datanetwerk op een bepaald moment in werking treden, zodat mensen niet langer in hetzelfde tempo kunnen schalen als de klantenkring. Zodra het AI-systeem snel genoeg verbetert, worden niet-gespecificeerde uitschieters minder frequent en kan het aantal mensen dat handmatige etikettering uitvoert worden verminderd of constant worden gehouden.
interessant voor: min of meer elke start van machine learning
voorbeelden:
- veel chatbot startups (waaronder Magic, GoButler, x.ai en Clara)
- Metamind (handmatig verzamelde en geëtiketteerde dataset voor voedselclassificatie)
- Gebouwradar (werknemers / stagiairs handmatig beelden van gebouwen labelen)
Strategie # 2: Beperk het domein
de meeste startups zullen proberen gegevens rechtstreeks van gebruikers te verzamelen. De uitdaging is om early adopters te overtuigen om het product te gebruiken voordat de voordelen van machine learning volledig in werking treden (omdat gegevens in de eerste plaats nodig zijn om de algoritmen te trainen en te fine-tunen). Een manier om deze catch-22 te omzeilen is om het probleemdomein drastisch te beperken (en de scope later uit te breiden indien nodig). Zoals Chris Dixon zegt: “de hoeveelheid data die je nodig hebt is relatief aan de breedte van het probleem dat je probeert op te lossen.”
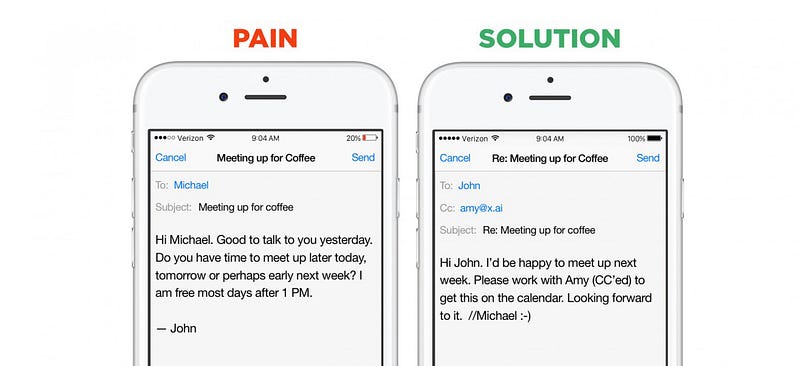
goede voorbeelden van de voordelen van een smal domein zijn opnieuw chatbots. Startups in dit segment kunnen kiezen tussen twee go-to-market strategieën: ze kunnen horizontale assistenten bouwen-bots die kunnen helpen met een zeer groot aantal vragen en onmiddellijke Verzoeken (voorbeelden zijn Viv, Magic,Awesome, Maluuba en Jam). Of ze kunnen verticale assistenten creëren-bots die een specifieke, goed gedefinieerde taak extreem goed proberen uit te voeren (voorbeelden zijn x.ai, Clara, DigitalGenius, Kasisto — Meekan – en meer recentgobutler / Angel. ai). Hoewel beide benaderingen geldig zijn, is het verzamelen van gegevens dramatisch gemakkelijker voor startups die closed-domain problemen aan te pakken.
Interessant voor: Verticaal geïntegreerde bedrijven
Voorbeelden:
- Zeer gespecialiseerde verticale chatbots (zoals x.ai, Clara of GoButler)
- Diep Genomics (gebruikt diep leren indelen/interpreteren genetische varianten)
- Gekwantificeerd Huid (maakt gebruik van de klant selfies analyseren van een persoon huid)
Strategie #3: Crowdsourcing / Outsourcing
in plaats van gekwalificeerde medewerkers (of stagiairs) te gebruiken om handmatig gegevens te verzamelen of te labelen, kunnen startups het proces ook crowdsourcen. Platforms zoals Amazon Mechanical Turk of CrowdFlower bieden een manier om rommelige en onvolledige gegevens op te ruimen met behulp van een online personeelsbestand van miljoenen mensen. Bijvoorbeeld, VocalIQ (overgenomen door Apple in 2015) gebruikt Amazon ‘ s Mechanische Turk om de digitale assistent duizenden gebruikersvragen voeden. Werknemers kunnen ook worden uitbesteed door het in dienst nemen van andere onafhankelijke aannemers (zoals gedaan door cyclara of Facebook M). De noodzakelijke voorwaarde voor het gebruik van deze aanpak is dat de taak duidelijk kan worden uitgelegd en is niet te lang/saai.

een andere tactiek is het stimuleren van het publiek om vrijwillig gegevens aan te dragen. Een voorbeeld is Snips, een Parijs-gebaseerde AI startup die deze aanpak gebruikt om zijn handen te krijgen op een bepaald type gegevens (bevestiging e-mails voor restaurants, hotels en luchtvaartmaatschappijen). Net als andere startups, Snips maakt gebruik van een gamified systeem waar gebruikers zijn gerangschikt op een leaderboard.
interessant voor: Gebruik de gevallen waar de kwaliteit van de controle kan gemakkelijk worden afgedwongen
Voorbeelden:
- DeepMind, Maluuba, AlchemyAPI en vele anderen (zie hier)
- VocalIQ (gebruikt Mechanische Turk te leren zijn programma hoe de mensen praten)
- Afsnijden (vraagt mensen om vrij te dragen gegevens voor onderzoek)
Strategie #4: Gebruiker-in-de-lus
Een crowdsourcing strategie die verdient een eigen categorie in de gebruiker-in-de-lus.Deze aanpak omvat het ontwerpen van producten die de juiste prikkels bieden voor gebruikers om gegevens terug te geven aan het systeem. Twee klassieke voorbeelden van bedrijven die deze aanpak hebben gebruikt voor veel van hun producten zijn Google(autocomplete in search, Google Translate, spamfilters, enz.) en Facebook (gebruikers taggen vrienden in foto ‘ s). Gebruikers zijn vaak niet op de hoogte dat ze deze bedrijven voorzien van gelabelde gegevens gratis.
veel startups in de machine learning ruimte hebben inspiratie getrokken uit Google en Facebook door het creëren van producten met een fout-tolerante UX die gebruikers expliciet aanmoedigen om machine fouten te corrigeren. Vooral opmerkelijk arere en Duolingo (beide opgericht door Luis von Ahn). Andere voorbeelden zijn Unbabel, Wit.ai en Mapillary.
Interessant voor: Consumer-centric startups met constante interactie met de gebruiker
Voorbeelden:
- Unbabel (gemeenschap van vertalers de juiste machine-gegenereerde vertalingen)
- Wit.ai (mits dashboard/API voor gebruikers om de juiste vertaling fouten)
- Mapillary (gebruikers kunnen de juiste machine gegenereerde traffic sign detection)
Strategie #5: Side business
een strategie die bijzonder populair lijkt te zijn bij starters van computer vision is het aanbieden van een gratis, domeinspecifieke mobiele app die gericht is op consumenten. Clarifai, HyperVerge en Madbits (overgenomen door Twitter in 2014) hebben allemaal deze strategie gevolgd door het aanbieden van foto-apps die extra beeldgegevens verzamelen voor hun core business.
deze strategie is niet geheel risicovrij (het kost immers tijd en geld om een app succesvol te ontwikkelen en te promoten). Startups moeten er ook voor zorgen dat ze een sterk genoeg use case creëren die gebruikers dwingt om hun gegevens op te geven, zelfs als de service de voordelen van datanetwerk-effecten in het begin mist.
interessant voor: startende ondernemingen/horizontale platforms
voorbeelden:
- Clarifai (Forevery, photo discovery app)
- HyperVerge (Silver, photo organization app)
- Madbits (Momentsia, photo collage app) )