Av Moritz Mueller-Freitag, Elleve Strategi.
den» urimelige effektiviteten » av data for maskinlæringsprogrammer har blitt mye diskutert gjennom årene (se her, her og her). Det har også blitt foreslått at mange store gjennombrudd Innen Kunstig Intelligens ikke har blitt begrenset av algoritmiske fremskritt, men av tilgjengeligheten av datasett av høy kvalitet (se her). Den røde tråden som går gjennom disse diskusjonene er at data er en viktig komponent i å gjøre toppmoderne maskinlæring.
Tilgang til opplæringsdata av høy kvalitet er avgjørende for oppstartsbedrifter som bruker maskinlæring som kjerneteknologi i sin virksomhet. Mens mange algoritmer og programvareverktøy er åpne hentet og delt på tvers av forskningsmiljøet, er gode datasett vanligvis proprietære og vanskelige å bygge. Å eie et stort, domenespesifikt datasett kan derfor bli en betydelig kilde til konkurransefortrinn, spesielt hvis oppstart kan hoppe på datanettverkseffekter (en situasjon der flere brukere → mer data → smartere algoritmer → bedre produkt → flere brukere).
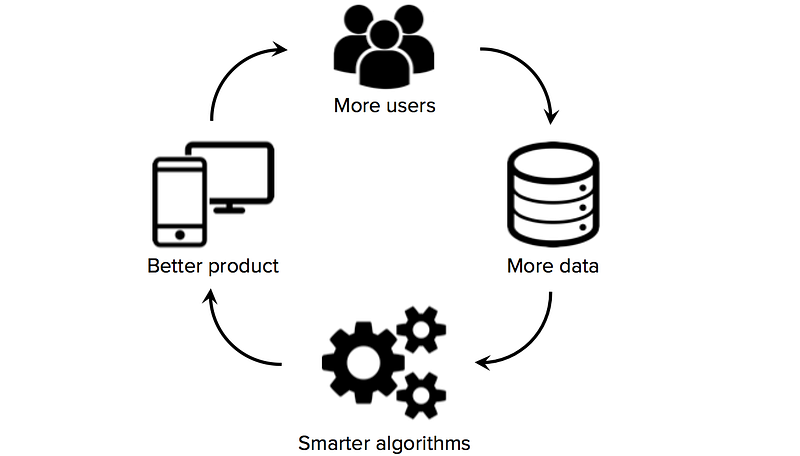
følgelig er en av de viktigste strategiske beslutningene som oppstart av maskinlæring må gjøre, hvordan man bygger datasett av høy kvalitet for å trene sine læringsalgoritmer. Dessverre har oppstart ofte begrensede eller ingen merkede data i begynnelsen, en situasjon som utelukker grunnleggere fra å gjøre betydelige fremskritt når det gjelder å bygge et datadrevet produkt. Det er derfor verdt å utforske datainnsamlingsstrategier fra begynnelsen, før du ansetter datavitenskapsteamet eller bygger opp en kostbar kjerneinfrastruktur.
Startups kan overvinne kaldstart problemet med datainnsamling på mange måter. Valget av data strategi / kilde går vanligvis hånd i hånd med valg av forretningsmodell, en oppstart fokus (forbruker eller bedrift, horisontal eller vertikal, etc.) og finansieringssituasjonen. Følgende liste over strategier, mens verken uttømmende eller gjensidig utelukkende, gir en følelse for det brede spekter av tilnærminger tilgjengelig.
Strategi #1: Manuelt arbeid
Å Bygge et godt proprietært datasett fra bunnen av betyr nesten alltid å sette mye opp foran, menneskelig innsats i datainnsamling og utføre manuelle oppgaver som ikke skaleres. Eksempler på oppstart som har brukt brute force i begynnelsen er rikelig. For eksempel bruker mange chatbot-oppstart menneskelige «AI-trenere» som manuelt oppretter eller verifiserer spådommene deres virtuelle agenter gjør (med varierende grad av suksess og høy omsetningsrate for ansatte). Selv tech gigantene ty til denne strategien: Alle svar Fra Facebook M er gjennomgått og redigert av et team av entreprenører.

bruk av brute force for å manuelt merke datapunkter kan være en vellykket strategi så lenge datanettverkseffekter sparker inn på et tidspunkt slik at mennesker ikke lenger skalerer i like takt med kundebasen. SÅ snart AI-systemet forbedrer seg raskt nok, blir uspesifiserte avvikere mindre hyppige, og antall mennesker som utfører manuell merking, kan reduseres eller holdes konstant.
Interessant for: Mer eller mindre hver oppstart av maskinlæring
Eksempler:
- Mange chatbot oppstart (inkludert Magi, GoButler, x.ai Og Clara)
- MetaMind (manuelt innsamlet og merket datasett for matklassifisering)
- Bygningsradar (ansatte/praktikanter merker manuelt bilder av bygninger)
Strategi # 2: Begrens domenet
De fleste oppstart vil prøve å samle inn data direkte fra brukere. Utfordringen er å overbevise tidlige adoptere til å bruke produktet før fordelene med maskinlæring fullt spark i (fordi data er nødvendig i første omgang å trene og finjustere algoritmer). En vei rundt denne catch-22 er å drastisk begrense problemdomenet (og utvide omfanget senere om nødvendig). Som Chris Dixon sier: «mengden data du trenger er i forhold til bredden av problemet du prøver å løse .»
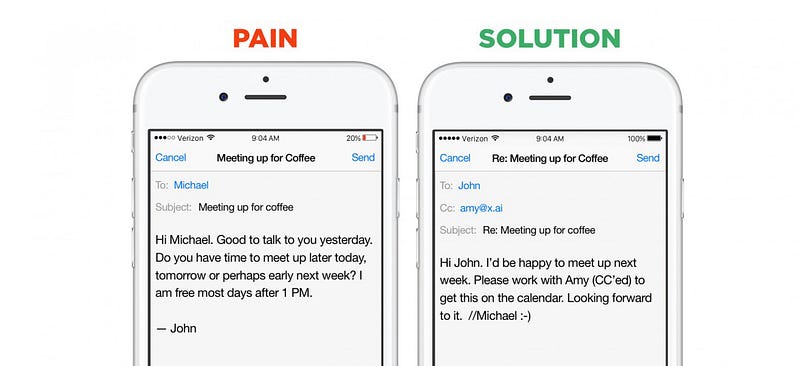
Gode eksempler på fordelene med et smalt domene er igjen chatbots. Startups i dette segmentet kan velge mellom to go-to-market strategier: de kan bygge horisontale assistenter-bots som kan hjelpe med et veldig stort antall spørsmål og umiddelbare forespørsler (eksempler Er Viv, Magic,Awesome, Maluuba og Jam). Eller de kan lage vertikale assistenter-bots som prøver å utføre en bestemt, veldefinert jobb ekstremt godt (eksempler er x.ai, Clara, DigitalGenius, Kasisto, Meekan — og mer nyliggobutler/Angel.ai). Mens begge tilnærmingene er gyldige, er datainnsamling dramatisk lettere for oppstart som takler problemer med lukkede domener.
Interessant for: Vertikalt integrerte virksomheter
Eksempler:
- høyt spesialiserte vertikale chatbots (for eksempel x.ai, Clara Eller GoButler)
- Dyp Genomikk(bruker dyp læring til å klassifisere / tolke genetiske varianter)
- Kvantifisert Hud (bruker kundens selfies til å analysere en persons hud)
Strategi # 3: Crowdsourcing / Outsourcing
I Stedet for å bruke kvalifiserte medarbeidere (eller praktikanter) til å samle inn eller merke data manuelt, kan oppstart også crowdsource prosessen. Plattformer som Amazon Mechanical Turk eller CrowdFlower tilbyr en måte å rydde opp rotete og ufullstendige data ved hjelp av en online arbeidsstyrke på millioner av mennesker. For eksempel brukte VocalIQ (kjøpt Av Apple i 2015) Amazons Mekaniske Turk til å mate sin digitale assistent tusenvis av brukerforespørsler. Arbeidere kan også outsources ved å ansette andre uavhengige entreprenører(som done byClara Eller Facebook M). Den nødvendige betingelsen for å bruke denne tilnærmingen er at oppgaven tydelig kan forklares og ikke er for lang/kjedelig.

En annen taktikk er å stimulere offentligheten til frivillig å bidra med data. Et eksempel er Snips, En Paris-basert AI-oppstart som bruker denne tilnærmingen til å få hendene på en bestemt type data (bekreftelsesemails for restauranter, hoteller og flyselskaper). Som andre oppstart bruker Snips et gamified system der brukerne er rangert på et leaderboard.
Interessant for: Bruk tilfeller der kvalitetskontroll lett kan håndheves
Eksempler:
- DeepMind, Maluuba, AlchemyAPI og mange andre (se her)
- VocalIQ (brukt Mechanical Turk til å lære sitt program hvordan folk snakker)
- Snips (ber folk fritt bidra med data til forskning)
Strategi # 4: User-in-the-loop
en crowdsourcing strategi som fortjener sin egen kategori er user-in-the-loop.Denne tilnærmingen innebærer å designe produkter som gir de rette incentivene for brukerne å gi data tilbake til systemet. To klassiske eksempler på selskaper som har brukt denne tilnærmingen for Mange av sine produkter Er Google (autofullfør i søk, Google Translate, spamfiltre, etc.) Og Facebook (brukere tagging venner i bilder). Brukere er ofte uvitende om at de gir disse selskapene med merket data gratis.
mange oppstart i maskinlæringsområdet har hentet inspirasjon Fra Google og Facebook ved å lage produkter med en feiltolerant UX som eksplisitt oppfordrer brukerne til å rette maskinfeil. Spesielt bemerkelsesverdig arere Og Duolingo (begge grunnlagt Av Luis von Ahn). Andre eksempler er Unbabel, Wit.ai Og Mapillary.
Interessant for: Forbruker-sentriske oppstart med konstant brukerinteraksjon
Eksempler:
- Unbabel (fellesskapsoversettere korrekt maskingenererte oversettelser)
- Wit.ai (gitt dashboard / API for brukere å korrigere oversettelsesfeil)
- Mapillary (brukere kan korrigere maskingenerert trafikkskilt deteksjon)
Strategi # 5: Side business
en strategi som synes å være spesielt populær blant oppstart av datasyn, er å tilby en gratis, domenespesifikk mobilapp som retter seg mot forbrukere. Clarifai, HyperVerge og Madbits (kjøpt Av Twitter i 2014) har alle fulgt denne strategien ved å tilby bildeapper som samler ytterligere bildedata for kjernevirksomheten.
denne strategien er ikke helt uten risiko (det koster jo tid og penger å utvikle og markedsføre en app). Oppstart må også sørge for at de skaper en sterk nok brukstilfelle som tvinger brukere til å gi opp dataene sine, selv om tjenesten mangler fordelene med datanettverkseffekter i begynnelsen.
Interessant for: Enterprise startups / horisontale plattformer
Eksempler:
- Clarifai (Forevery, foto oppdagelse app)
- HyperVerge (Sølv, foto organisasjon app)
- Madbits (Momentsia, foto collage app)