이 문서는 마이크로 컨트롤러 코어가 설계되는 방법을 학습에 초점을 맞추고,교육 용도로만 사용됩니다. 방문하시기 바랍니다 www.zilog.com 그리고 프로젝트의 요구에 맞는 마이크로 컨트롤러를 선택 제조 업체의 제품 라인을 확인(8 비트에서! 이 모든 것은 매우 간단합니다. 진보된 모터 통제 기능을 포함하는지 어느 것이).
마이크로컨트롤러와 마이크로프로세서와의 연애는 1988 년 세펫 홍보(쿠리치바에 위치한 4 년제 브라질 중등/기술 학교 및 대학)에서 기술 학위를 취득할 때 시작되었습니다. 나는 고전적인 질로그를 탐험하면서 기초를 배우는 것으로 시작했다.

위키미디어 공용 에 관련된미디어 분류가 있습니다.
마이크로컨트롤러 프로그래밍에 관한 책을 저술하고(자료 참조),작은 디자인 하우스를 시작하고,세펫-사우스 캐롤라이나(플로리아노폴리스에 위치한 또 다른 브라질 대학)에서 졸업 후 프로그램을 끝내는 프로그래밍 경력을 통해 빨리 감긴다. 2008 년,프로그래밍 가능한 로직 및 가상 디스크와 더 많은 접촉이 있었고 호기심이 절정에 달했습니다. 몇 년이 지난 2016 년,저는 매우 저렴한 필드 프로그래밍 가능 게이트 어레이 키트를 발견하고 기회를 주기로 결심했습니다.
소프트코어를 디자인하는 것보다 더 좋은 점은 무엇입니까? 나는 현대 지-80 상대를 선택했다. (일명,에스 8;그림 1 비).

그림 1 비.
간단하면서도 강력한 명령어 세트와 아주 좋은 온칩 디버거를 갖춘 8 비트 마이크로 컨트롤러 코어입니다. 이것은 수학적으로 정확한 유형 계층구조인,강력한 타입을 정의합니다.
다이빙을 하기 전에 깊이의 핵심 운영,VHDL,Fpga,자 한 눈에 자일 로그 Z8 앙코르! 특징.

그림 1 씨.
8 비트 마이크로컨트롤러 제품군입니다. 최대 4,096 바이트의 램(파일 레지스터 및 특수 기능 레지스터 영역),최대 64 킬로바이트의 프로그램 메모리(일반적으로 플래시 메모리),최대 64 킬로바이트의 데이터 메모리(램). 또한 프로그래밍 가능한 우선순위를 갖는 벡터화된 인터럽트 컨트롤러와 비동기식 직렬 통신을 사용하여 호스트 컴퓨터와 통신하는 온칩 디버거를 포함한다. 이 마이크로 컨트롤러는 다양한 16 비트 타이머에서 모터 제어 타이머에 이르기까지 매우 멋진 주변 장치 세트로 포장되어 있습니다.www.zilog.com 전체 제품 라인을 확인).
이즈 8 프로그래밍 모델의 주요 특징 중 하나는 고정 축전지가 없다는 것이다. 대신 4,096 개의 가능한 램 주소 중 어느 것도 축전지로 작동 할 수 있습니다. 이 두가지 기능은 다음과 같습니다. 이를 위해 램은 레지스터 그룹으로 분할됩니다(각각 16 개의 작업 레지스터로 구성된 256 개의 그룹이 있습니다). 명령어는 일반적으로 단일 작업 레지스터 그룹 내에서 작동합니다. 이 문서는 기계 번역되었으므로 어휘,구문 또는 문법에서 오류가 있을 수 있습니다
명령어 집합과 관련하여 83 개의 서로 다른 명령어가 두 개의 연산 코드 페이지로 나뉩니다. 여기에는 덧셈,뺄셈,논리 연산,데이터 조작 명령어,이동 명령어,흐름 변경 명령어,일부 16 비트 명령어,비트 테스트 및 조작,8 곱하기 등과 같은 기본 작업에 대한 일반적인 명령어로 구성됩니다.
프로그램 메모리 영역은 첫 번째 주소가 특수 목적으로 전용되도록 구성됩니다. 주소 0 과 00002 및 00003 재설정 벡터를 저장합니다. 표 1 은 프로그램 메모리 구성을 보여줍니다.
| 0x0000 | Option bytes |
| 0x0002 | Reset vector |
| 0x0004 | WDT vector |
| 0x0006 | Illegal instruction vector |
| 0x0008 to 0x0037 | Interrupt vectors |
| 0x0038 to 0xFFFF | User program memory area |
TABLE 1. Simplified program memory organization.
일부 장치에는 두 번째 데이터 공간(최대 65,536 주소)이 포함되어 있습니다. 이 영역은 덜 사용되는 데이터를 저장하는 데 사용할 수 있습니다(읽기/쓰기가 램/소프트웨어 영역보다 느리기 때문에).하나는 프로그램 메모리 용이고 다른 하나는 레지스터 메모리 용입니다. 나는 데이터 메모리 영역을 포함하지 않기로 한 바와 같이,이 명령은 구현되지 않습니다.프로그램 메모리 버스는 16 비트 명령어 주소 버스,8 비트 명령어 데이터 버스,8 비트 명령어 데이터 버스,8 비트 명령어 데이터 버스,8 비트 명령어 쓰기 데이터 버스,8 비트 명령어 쓰기 데이터 버스,8 비트 명령어 쓰기 데이터 버스,8 비트 명령어 쓰기 데이터 버스,8 비트 명령어 쓰기 데이터 버스,8 비트 명령어 쓰기 데이터 버스,8 비트 명령어 쓰기 데이터 버스, 동기식 블록 램을 사용하여 구현된 16,384 바이트의 프로그램 메모리를 포함합니다(이는 장치의 전원이 꺼질 때 프로그램 메모리 내용이 손실됨을 의미합니다).
5 개의 레지스터 영역 버스는 파일 레지스터 영역(사용자 램)을 위해 3 개,특수 기능 레지스터 전용 2 개를 포함한다. 이 데이터 버스에는 8 비트 레지스터 출력 데이터 버스,8 비트 레지스터 출력 데이터 버스,8 비트 레지스터 출력 데이터 버스,8 비트 레지스터 출력 데이터 버스,8 비트 레지스터 출력 데이터 버스,8 비트 레지스터 출력 데이터 버스,8 비트 레지스터 출력 데이터 버스,8 비트 레지스터 출력 데이터 버스,8 비트 레지스터 출력 데이터 버스,8 비트 레지스터 출력 데이터 버스,8 비트 레지스터 출력 데이터 버스, 동기식 블록 램을 사용하여 구현된 2,048 바이트의 사용자 램 메모리를 포함한다.
그림 2 는; 중앙 처리 장치,두 개의 메모리 장치(하나는 프로그램 저장 용이고 다른 하나는 데이터 저장 용)및 외부 타이머 모듈을 볼 수 있습니다.
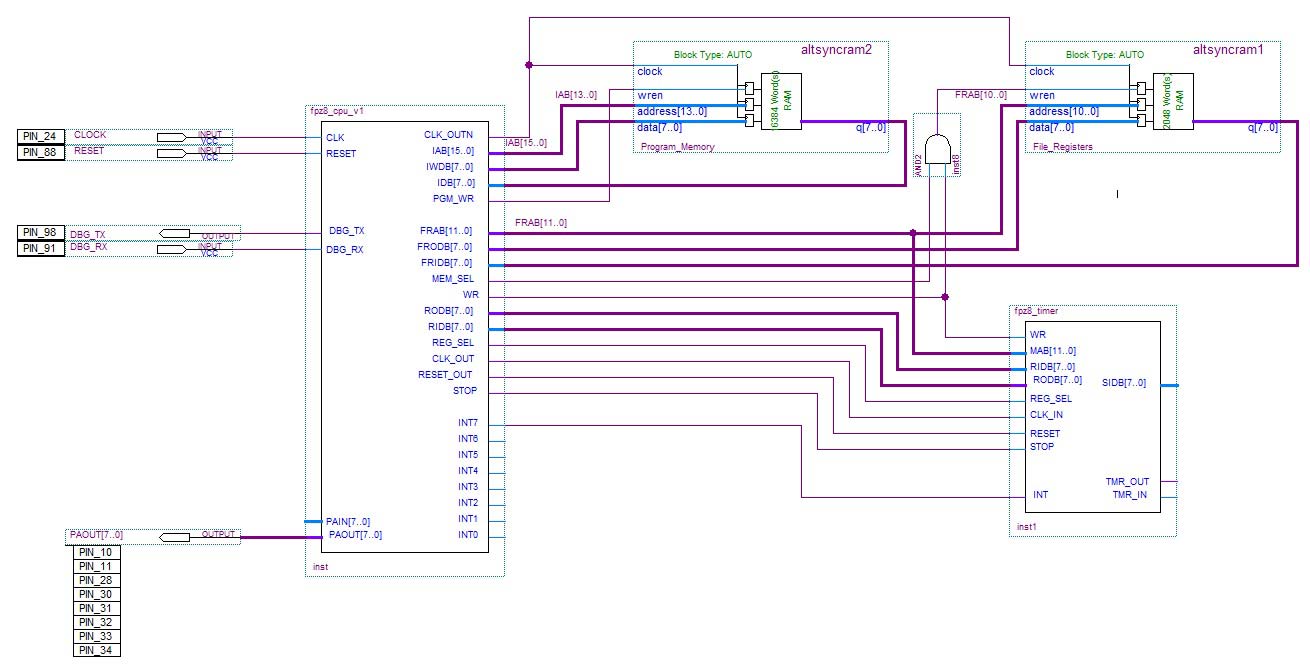
그림 2. 블록 다이어그램.
이 프로젝트의 상호 연결에 양방향 버스를 사용하지 않습니다. 단방향 버스는 공간 효율이 낮지만 사용하기가 더 간단합니다.그래서 이해를 쉽게하기 위해 그 작업을 일부 모듈로 나눌 것입니다:
- 명령어 큐잉 엔진
- 명령어 디코딩
- 인터럽트 처리
- 디버거
명령어 큐잉 엔진
명령어 페치 작업은 모든 프로세서에 대한 기본 작업입니다. 하버드 아키텍처는 동시 페치 및 데이터 액세스를 가능하게합니다(명령 및 데이터를위한 별도의 버스로 인해). 즉,다른 하나는 데이터 메모리에 읽거나 쓰는 동안 새 명령을 가져올 수 있습니다.(명령어 길이는 1 바이트에서 최대 5 바이트까지 다양함); 일부 지침은 길지만 다른 지침보다 빠르게 실행됩니다. 이 방법은 1 바이트의 길이를 가지며 2 사이클에서 실행되는 반면,4 바이트의 길이는 2 클럭 사이클에서 실행됩니다.
그렇다면 어떻게이 모든 지침을 성공적으로 디코딩 할 수 있습니까? 즉,프로그램 메모리에서 바이트를 가져 와서 8 바이트 배열에 저장하는 메커니즘입니다.
IAB<=PC;
IQUEUE.4369>큐.4369>큐.2015 년 :=0;
큐.이 문제를 해결하려면 다음을 수행하십시오.다음 중 하나를 수행합니다.대기열(대기열.WRPOS):=IDB;
FETCH_ADDR:=FETCH_ADDR+1;
IAB<=FETCH_ADDR;
IQUEUE.다음 예제는 다음과 같습니다.4369>큐.다음 예제는 다음과 같습니다.이 예제에서는 다음과 같은 방법을 사용합니다.그런 다음 다음을 수행하십시오.전체:=’1′;그렇지 않으면 큐.전체:=’0′;
종료 경우;
목록 1. 명령 큐 엔진.
페치는 일부 특수한 경우(인터럽트 처리,인터럽트 처리 또는 디버거 액세스)에서 비활성화할 수 있는 주 활성화 신호에 의해 제어됩니다. 여러 내부 매개 변수(가져 오기 상태,읽기 및 쓰기 포인터,큐 배열 자체,카운터 및 전체 표시기)를 저장하는 구조(큐)도 있습니다.
큐 카운터는 큐에서 사용할 수 있는 바이트 수(읽기)를 식별하는 데 사용됩니다. 디코더 단계는 이 번호를 사용하여 명령에 대한 원하는 바이트 수가 큐에서 이미 사용 가능한지 확인합니다.
명령어 디코딩
이것은 실제 마법이 일어나는 곳입니다. 명령 디코더는 명령 큐에서 옵 코드를 읽고 해당 작업으로 변환합니다.
명령어 디코더 설계는 모든 명령어와 주소 지정 모드 간의 관계를 파악하여 시작되었습니다. 일부 지침(그림 3)은 열별로 그룹화되어 있음을 쉽게 알 수 있습니다. 이 단일 바이트 명령어에서 높은 니블은 소스/대상 레지스터를 지정하고 낮은 니블은 명령어 자체를 지정합니다.
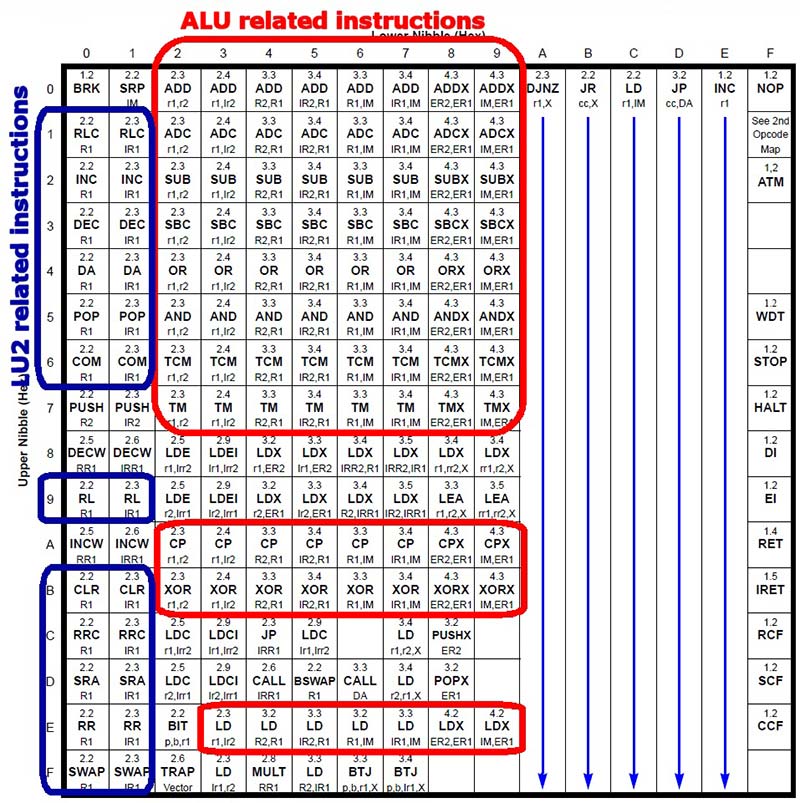
그림 3. 그룹 별 코드.
대부분의 지침은 몇 가지 기본 규칙에 따라 분류 할 수 있습니다:
- 열(연산 코드의 낮은 니블)은 일반적으로 주소 지정 모드를 지정합니다: 두 번째 바이트는 즉시 피연산자이고 마지막 두 바이트는 대상 확장 주소입니다.
- 행(연산 코드의 높은 니블)은 일반적으로 작업을 지정합니다.행 0 을 보면 열 0 과 열 1 은 명령어이고,열 0 은 명령어이고,열 0 은 명령어이고,열 0 은 명령어이고,열 0 은 명령어이고,열 0 은 명령어이다. 그래서 우리는 입력(연산 코드에서 더 높은 니블)으로 니블을 취하고 그에 따라 디코딩하는 알루를 디자인 할 수 있습니다. 이 열은 0 엑스 2 에 0 엑스 9 에 대해 작동하지만 처음 두 열에 대한 또 다른 접근 방식이 필요합니다.
그래서 나는 두 개의 단위를 작성하게되었다:대부분의 산술 및 논리 명령어에 집중하는 하나의 알루;그리고 두 번째 단위(논리 단위 2 또는 루 2)는 열에 표시된 다른 작업을 수행합니다. 알루 및 루 2 에 대한 연산 코드는 그림 3 에 표시된 연산 코드 행과 일치하도록 선택되었습니다.
또 다른 중요한 세부 사항은 동일한 열 및 그룹 내의 모든 명령어가 바이트 단위로 동일한 크기이므로 동일한 디코더 섹션에서 디코딩 될 수 있다는 것이다.
디코더 설계는 각 클럭 틱에서 진행되는 대형 유한 상태 시스템을 사용합니다. 모든 명령어는 다음과 같이 시작됩니다. 이것은 디코더가 실제로 옵코드를 디코딩하고,버스 및 내부 지원 신호를 준비하고,다른 실행 상태로 단계를 밟는 곳입니다. 이 모든 주 중에서 두 가지는 많은 지침에 의해 널리 사용됩니다. 당신은 이유를 추측 할 수? 당신은 그들이 알루와 루 2 에 관련되어 있기 때문에 말했다 경우,당신은 절대적으로 옳다!메모리 액세스가 부족하고 모든 알루 관련 명령어에 대한 마지막 상태(추가,추가,서브,서브,서브,서브,서브,또는,또는,및,및,및,및,및,및,및,및,및,및,및,및,및,및,및,및,및,및,및,및,및,및,및,및,및,및,및,및,및,및,및,및,및,및,및 이 명령어에는 다음과 같은 명령어가 포함되어 있습니다.
그림 4 를 참조하십시오.
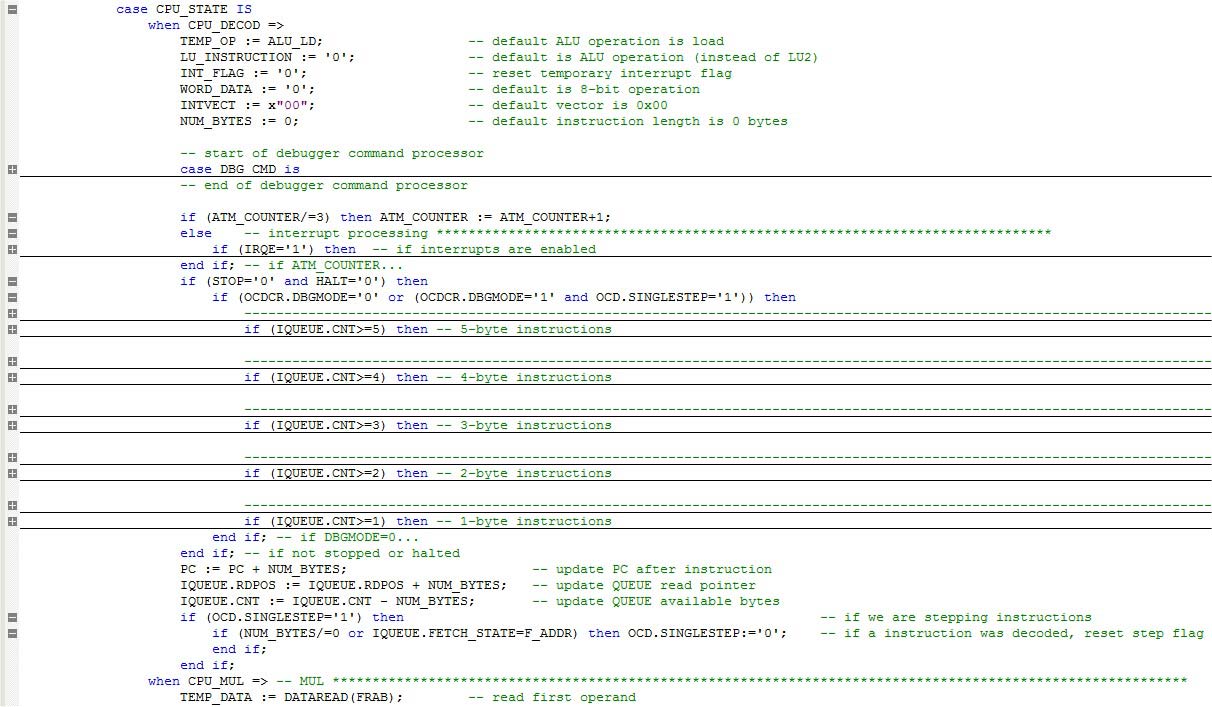
그림 4. 상태.
처음에는 일부 임시 변수가 기본 조건으로 초기화됩니다. 이 명령 디코더에 의해 소비 된 얼마나 많은 바이트를 제어하기 때문에 숫자 바이트는 매우 중요합니다. 이 값은 이 단계의 마지막 부분에서 컴퓨터(프로그램 카운터)를 증가시키고,큐 읽기 포인터를 진행하고,큐에서 사용 가능한 바이트 수를 줄이기 위해 사용됩니다.
초기화 섹션에 이어 인터럽트 처리 섹션을 볼 수 있습니다. 시스템 자원을 많이 사용하는 윈도우 매니져에 싫증이 난다면,이 패키지는 상당히 흥미있을 것입니다. 나는 다음 섹션에서 이것을 다룰 것이다.
실제 명령어 디코딩 블록은 저전력 모드가 활성화되어 있지 않은지,디버거 모드가 꺼져 있는지 확인합니다.2014. 또는 디버그 모드에있는 동안 단일 단계 디버그 명령이 실행되었습니다.1 과 강박증.단일 단계=1). 그런 다음 큐에서 사용 가능한 바이트를 확인하고 디코딩을 진행합니다.일부 명령어(대부분 단일 바이트 명령어)는 완전히 완료될 때까지 여러 상태가 필요한 반면,일부 명령어(대부분 단일 바이트 명령어)는 완전히 완료될 때까지 여러 상태가 필요합니다.
일부 명령어 디코딩은 특별히 작성된 여러 기능 및 프로시저를 사용할 수 있습니다.:
- 데이터 라이트-이 절차는 쓰기 작업을 위해 버스를 준비합니다. 그것은 대상이 내부 보안 장치,외부 보안 장치 또는 사용자 램 위치인지 여부를 선택합니다.이 함수는 데이터 라이트에 대한 상호 함수입니다. 그것은 소스 주소를 읽는 데 사용되며 자동으로 내부 보안 장치,외부 보안 장치 또는 사용자 램 위치인지 여부를 선택합니다.
- 조건 코드-조건부 명령어에 사용됩니다. 4 비트 조건 코드를 사용하여 테스트하고 결과를 반환합니다.
- 주소 4,주소 8 및 주소 12-이러한 함수는 4 비트,8 비트 또는 12 비트 소스에서 12 비트 주소를 반환합니다. 그들은 최종 12 비트 주소를 생성 하는 라인란 트 레지스터의 콘텐츠를 사용 합니다. 주소 8 과 주소 12 는 이스케이프 된 주소 지정 모드를 확인합니다.
- 가산기 16-주소 오프셋 계산을 위한 16 비트 가산기입니다. 8 비트 부호있는 피연산자를 사용하고 부호를 확장하여 16 비트 주소에 추가하고 결과를 반환합니다.
- 알루 및 루 2—이들은 이전에 논의되었으며 대부분의 산술 및 논리 연산을 수행합니다.
인터럽트 처리
전에 말했듯이,이지에지 8 은 프로그래밍 가능한 우선 순위를 가진 벡터화된 인터럽트 컨트롤러가 있다. 처음에,나는 인터럽트가 더 큰 문제가 없기 때문에이 부분이 그렇게 어렵지 않을 것이라고 생각,권리? 글쎄,필요한 모든 작업(컨텍스트 저장,벡터링,우선 순위 관리 등)을 수행하는 방법을 알아 내기 시작했을 때),나는 그것이 내가 처음 생각했던 것보다 더 강하다는 것을 깨달았다. 몇 시간 후,나는 현재의 디자인을 내놓았다.
이것은 수학적으로 정확한 유형 계층구조인,강력한 타입을 정의합니다. 이 디자인은 활성화 된 인터럽트에 관한 인터럽트 이벤트를 감지 할 때 벡터 주소를 생성하는 중첩 된 체인을 사용합니다.
그림 5 는 인터럽트 시스템의 압축된 보기를 보여줍니다. 참고 기호가 있는 경우 첫 번째 문이 있습니다. 이것은(이 원자 작업을 허용,세 명령 사이클 인터럽트를 비활성화)현금 지급기 명령에 의해 사용되는 간단한 카운터입니다.
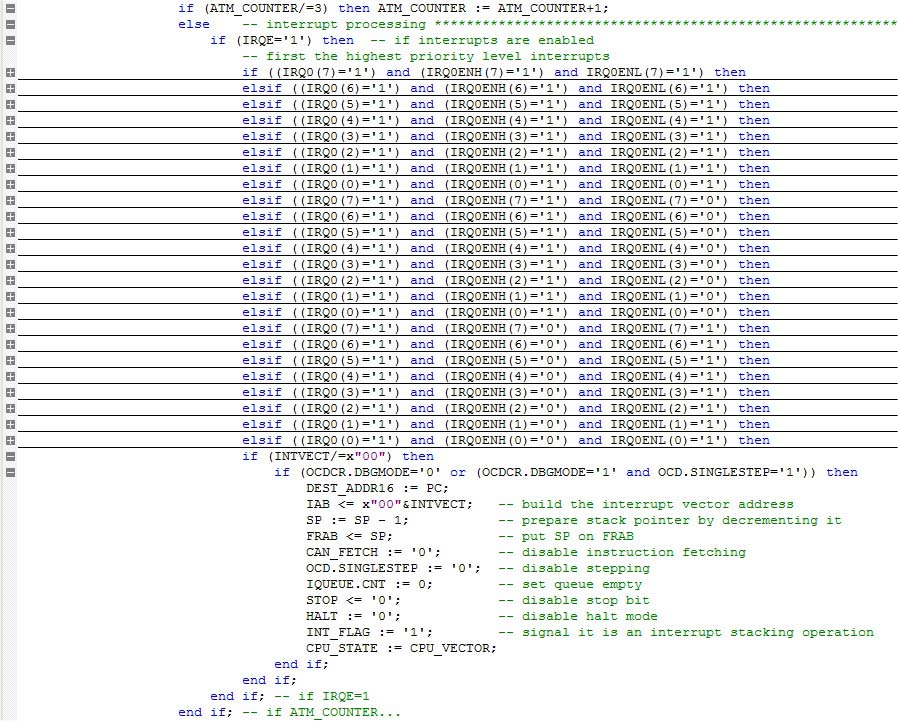
그림 5. 인터럽트 시스템.
인터럽트에 관한 마지막 코멘트: 인터럽트 플래그 레지스터는 시스템 클럭의 상승 에지마다 인터럽트 입력을 샘플링합니다. 또한 플래그의 현재 상태와 마지막 상태를 저장하는 두 개의 버퍼 변수가 있습니다. 이를 통해 인터럽트 에지 감지가 가능하며 외부 입력을 내부 클럭과 동기화합니다.
온칩 디버거
이것은 아마 상업 통합 개발 환경(아이디)을 허용으로이 소프트 코어의 멋진 기능입니다; 이 응용 프로그램은 다음과 같은 기능을 제공합니다. 온칩 디버거(강박증)는 자동 전송 기능과 명령 프로세서가 연결된 유아트로 구성됩니다. 명령 및 데이터를 디버그 명령을 처리하는 디버거 상태 머신에 전달합니다.

그림 6. 온칩 디버거
내 강박증 디자인은 실제 하드웨어에서 사용할 수있는 거의 모든 명령을 구현합니다.
내가 강조하고 싶은 한 가지는 비동기 신호를 처리 할 때주의가 필요하다는 것입니다. 내 첫 번째 디자인은 입력 신호를 처리하는 동안 그것을 고려하지 않았습니다. 결과는 절대적으로 이상했습니다. 내 디자인은 시뮬레이션에서 완벽하게 작동했습니다. 나는 그것을 다운로드하는 FPGA 와 문제점을 탐색하기 시작했으로 디버깅 직렬 인터페이스에 의 시리얼 터미널을 사용하는(내 FPGA 보드에 내장형 시리얼 USB 변환).
놀랍게도,대부분의 경우 명령을 성공적으로 보내고 예상 결과를 수신 할 수 있지만 때로는 디자인이 단순히 정지되어 응답을 중지 할 수도 있습니다. 소프트 리셋은 일이 자신의 적절한 작동으로 돌아 갈 것,하지만 날 흥미로운했다. 무슨 일이야?
많은 테스트와 일부 인터넷 검색 후에 직렬 입력 신호의 비동기 에지와 관련이있을 수 있음을 알았습니다. 그런 다음 내 내부 시계에 신호를 동기화 할 수있는 계단식 래치를 포함하고 모든 문제는 사라졌다! 그것은 당신이 항상 복잡한 논리로 그들을 공급하기 전에 외부 신호를 동기화해야한다는 것을 배울 수있는 힘든 방법입니다!
디버거 코드를 디버깅하고 구체화하는 것이 이 프로젝트에서 가장 어려운 부분이라고 말해야 합니다.2555>일단 완전히 컴파일되면 4,900 개의 논리 요소,523 개의 레지스터,147,456 비트의 온칩 메모리 및 1 개의 내장 된 9 비트 승수를 사용했습니다. 이 리소스는 사용 가능한 리소스의 80%를 사용합니다. 이것이 많은 것이지만 주변 장치에 사용할 수있는 1,200 개의 논리 요소가 여전히 있습니다(간단한 16 비트 타이머는 최대 약 120 개의 논리 요소와 61 개의 레지스터를 추가합니다). 이 모델은 제가 여기서 사용한 저비용 미니 보드에 장착된 것입니다(그림 7).

그림 7. 미니 보드.2555>
그러나 내가 구입 한 패키지에는 외부 프로그래밍 동글도 포함되어 있습니다.
실제 세계 테스트는 말할 필요도없이 처음으로 작동하지 않았습니다! 조금 생각하고 컴파일러 출력 메시지를 읽은 후,나는 그것이 아마도 타이밍 문제라는 것을 알아 냈습니다. 이것은 프로그래밍 가능한 논리로 디자인 할 때 매우 일반적인 딜레마입니다.
타이밍 분석 메시지를 확인,나는 최대 클럭이 약 24 메가 헤르츠해야한다는 경고를 볼 수 있었다. 처음엔 25 메가 헤르츠 프로세서 클럭을 생성하기 위해 디바이더 별 2 를 사용하려고 시도했지만 신뢰할 수는 없었습니다. 그런 다음 구분선 별 3 을 사용했습니다. 모든 것이 완벽하게 작동하기 시작!그 이유는 다음과 같습니다. 24 메가 헤르츠보다 낮지 만 16.666 메가 헤르츠보다 높은 클럭을 얻기 위해 메인 클럭을 곱하거나 나누기 위해 내부 플러 중 하나를 사용하여 더 높은 속도를 얻을 수 있습니다.
프로그래밍 및 디버깅
이 프로그램을 다운로드하면 메모리에 로드된 프로그램이 실행되기 시작합니다. 16 진수 파일을 제공하고 메가 마법사 플러그인 관리자를 사용하여 프로그램 메모리 초기화 파일을 변경할 수 있습니다. 이렇게 하면 재설정 신호에 따라 응용 프로그램 코드가 실행되기 시작합니다.
사용할 수 있는 자일 로그 ZDS-II IDE 쓰 어셈블리 또는 코드,그리고 생성하는 데 필요한 hex 파일을(나는 일반적으로 선택하 Z8F1622 로 내 목표는 장치로 그것은 또한 2 개의 KB RAM16KB 프로그램의 메모리). 온칩 디버거 덕분에 직렬 디버그 연결을 사용하여 코드를 다운로드 할 수 있습니다(이 경우).
연결하기 전에 디버거 설정이 그림 8 과 같은지 확인하십시오. “깜박이기 전에 페이지 지우기 사용”옵션의 선택을 취소하고 현재 디버그 도구로”직렬스마트 가능”을 선택하십시오. 또한 디버그 포트(설정 버튼 사용)로 올바르게 선택 되어 있는지 확인 하는 것을 잊지 마세요. 당신은뿐만 아니라 원하는 통신 속도를 설정할 수 있습니다;115,200 초당 나를 위해 아주 잘 작동합니다.
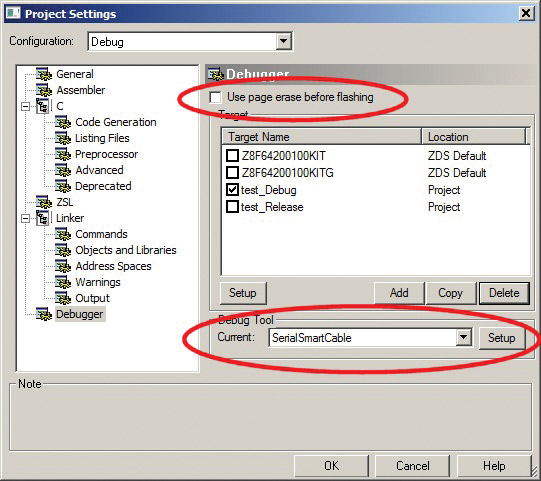
그림 8. 디버거 설정.
대상 장치가 프로젝트와 같지 않다는 경고 메시지가 표시됩니다. 그것은 내가 일부 아이디 메모리 영역을 구현하지 않았기 때문에 발생합니다. 경고를 무시하고 디버깅 세션을 계속 진행하십시오.
코드가 성공적으로 다운로드되면 응용 프로그램(이동 버튼),단계 지침,레지스터 검사 또는 편집,중단 점 설정 등을 시작할 수 있습니다. 다른 좋은 디버거와 마찬가지로,당신은,예를 들어,패 아웃 레지스터를 선택할 수 있습니다(포트 그룹 아래)심지어 패 아웃에 연결된 디딜 방아의 상태를 변경.
몇 가지 간단한 코드 예제는 다운로드에서 찾을 수 있습니다.
따라서 다운로드한 모든 프로그램은 전원이 꺼지면 손실됩니다.
마감
이 프로젝트를 완료하는 데 몇 주가 걸렸지 만 마이크로 컨트롤러 코어를 연구하고 설계하는 것은 즐거웠습니다.
이 프로젝트가 컴퓨팅 기본 사항,마이크로 컨트롤러,임베디드 프로그래밍 및/또는 가상 컴퓨터에 대해 배우고 싶은 모든 사람들에게 유용 할 수 있기를 바랍니다. 이 응용 프로그램은 당신에게 아름다운 욕실 꾸미기의 갤러리를 보여줍니다 재미를!
세펫-홍보:
www.utfpr.edu.brwww.sctec.com.br
:
https://www.amazon.com/HCS08-Unleashed-Designers-Guide-Microcontrollers/dp/1419685929
2018 년 11 월 1 일(토)~12 월 1 일(일)zilog.com/docs/UM0128.pdf
Zilog Z8F64xx Product Specification (PS0199):
www.zilog.com/docs/z8encore/PS0199.pdf
Zilog ZDS II IDE User Manual (UM0130):
www.zilog.com/docs/devtools/UM0130.pdf
Zilog ZDS-II Software Download:
https://www.zilog.com/index.php?option=com_zcm&task=view&soft_id=7&Itemid=74
Zilog Microcontroller Product Line:
http://zilog.com/index.php?option=com_product&task=product&businessLine=1&id=2&parent_id=2&Itemid=56
Project Files available at:
https://github.com/fabiopjve/VHDL/tree/master/FPz8
FPz8 at Opencores.org:
http://opencores.org/project,fpz8