オンラインショッピングでは検索とナビゲーションが最も重要です。 ユーザーが特定のものを検索するときは、関連する製品が短時間でユーザーに表示されることが重要です。 これを行うには、オンラインショッピング会社の管理者は、検索エンジンのさまざまな側面を管理するための強力なツールを与えられるべきです。
これはEndeca searchが行うことです。 それは彼らのウェブサイトの調査の経験を管理するのを助けるように電子商取引の場所の所有者用具を提供する。
ウェブサイトに検索を追加
Oracle Endecaとは何ですか?
エンデカという言葉は”発見する”という意味です。 Endecaは1999年に、会社創設され、主に焦点を合わせます–
- 電子商取引。
- エンタープライズ検索。
- ビジネスインテリジェンス。
従来の電子商取引の在庫照会システムでは、男性の服や女性の服を選択し、男性のズボン、男性のシャツ、男性のコートなどから選択することから始ま 最終的に、あなたは黒の36インチの男性のズボンに着くだろうが、それは非常に線形で、データを介して”ガイド付き”のルートでした。 対照的に、Endecaの検索技術を使用したwebサイトでは、片側に寸法と属性のリストが表示され、ユーザーは検索を絞り込むために任意の選択を行うことができ このすべては、顧客が維持することは非常に簡単だったバックエンドで、高速軽量化が起こりました。
そこでEndecaはこのeコマース市場に最初に焦点を当て、これをサポートするためにMDEXエンジンを開発し、さまざまな”ギザギザ”のデータセット(つまり、同じデータモデルを持たないが、それらの間にいくつかの共通性を持つデータセット)にわたって”ファセット検索”を可能にする列ストア、迅速な開発クエリエンジンとしてマーケティングした。
Endecaの用語についての簡単な紹介-
Endecaは、構造化データと非構造化データの両方の大規模なスケールにスケールするシンプルなユーザーインターフェイスを使用して、ユーザーにデータと対話して分析するシンプルで簡単な方法を提供したいと考えていました。
Endeca searchは、複数のデータソースからあらゆるサイズのデータを検索、ナビゲート、分析するユーザーのニーズに対応しています。 それはまた次元を渡って切れ、さいの目に切り、最も良い細部にあくか、またはデータの巨視的な眺めを持っていることを助ける。 また、ユーザーは複雑な検索クエリを簡単に実行できるはずです。
Oracle Endeca guided navigationは、問合せの検索結果を提供することに加えて、次のステップをユーザーに伝えることができます。 これらの提案は、はるかに優れたユーザーナビゲーション体験を提供するのに役立ちます各クリックで再ランク付けされ、再編成されています。
Oracle Endeca Guided Searchコンポーネント
Oracle Endeca Guided Searchには、主に三つのコンポーネントがあります。
これらのコンポーネントは:
- Endeca Information Transformation Layer(ITL)
- Endeca MDEX Engine
- Endeca Application Tier
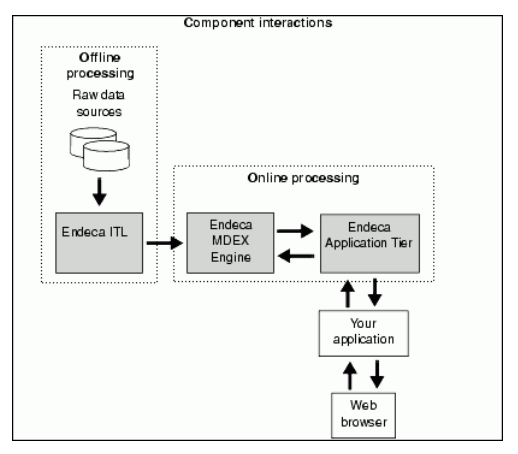
Endeca information transformation layer(ITL)は生のソース-データを読み取り、Oracle Endeca MDEX engineインデックスに変換します。 ITLは、
- コンテンツ取得システムで構成されています。
- Endeca CASサーバおよびコンソール
- CAS API
- Endeca webクローラー。
- Data Foundry
- Forge(データ操作プログラム)。
MDEXとは、ORACLE DatabaseやOracle EssbaseなどのOracle製品とどのように比較されますか。
まず、ESSBASEキューブやOracleリレーショナル-データベースなどと比較して、MDEXの背後にある設計目標を理解する価値があります。 Oracleデータベースは、多くの詳細レベル-データを可能な限りスペース効率の高い方法で格納し、個々のデータ行の取得時間を短縮するように設計されています; Essbaseキューブは、多くの詳細レベルのデータを事前に計算して集計し、そのスライスを迅速に提供するように設計されており、ユーザーが使用するクエリパスに MDEXはEndeca search and discovery uses caseをサポートするように設計されていますが、ユーザーは任意に検索してフィルタリングし、高速に集計されたビューを返すことができます。 そのように、Endecaは多様で、急速に変化する、データの分析のために設計されている雑種の調査/分析的なデータベースとしてMDEXを置く。
Oracle Endeca MDEXエンジンは、Oracle Endecaガイド付き検索の問合せエンジンです。 それは含んでいます-
- インデクサー(Dgidx)。
- Agraph
ITL層によって生成されたインデックスはMDEXエンジンを介してロードされます。
インデックスがロードされると、MDEXエンジンはアプリケーション層から検索クエリを受信し、インデックスと照合して関連する結果をユーザーのwebブラウ
アプリケーション層はMDEXエンジンへのインターフェイスを提供します。
アプリケーション層はMDEXエンジンへのインターフェイスを提供します。 同じアプリケーションで使用できる2つの既定のインターフェイスは、Presentation APIとWebサービスインターフェイスです。
プレゼンテーションAPIとwebサービスインターフェイスは、MDEXエンジンのクエリと結果の変更に使用されます。 ForgeなどのITLコンポーネントは、ビジネスニーズに応じて特定の期間にオフラインで実行されます。 MDEXエンジンとEndecaアプリケーション層は、クライアントがデータにアクセスできるようにするときにオンラインである必要があります。
これらのインターフェイスは、MDEXエンジンを照会し、結果を操作するために使用されます。 ForgeなどのEndeca ITLコンポーネントは、ビジネス要件に適した間隔でオフラインで実行されます。 Endeca MDEX EngineとEndeca Application Tierはどちらもオンラインプロセスであるため、クライアントがデータ・セットにアクセスできるようにする必要があります。
Endeca MDEXエンジンのクエリ結果
Endeca MDEXエンジンは、2種類の情報を返します。
- クエリの結果(レコードセットまたは単一レコード)。
- 構築のためのサポート情報は、クエリに従います。 (この情報は、ユーザーがファセットとフィルタを使用して検索クエリを絞り込むか、拡張するのに役立ちます。)
Endeca MDEXエンジンから返されるすべてのクエリ結果には、2種類の情報が含まれています。 これらの情報タイプは、
- クエリに適した結果(レコードセットや個々のレコードなど)
- フォローオンクエリを構築するためのサポート情報フォローオンクエリ情報を使用すると、ユーザーはクエリとそれに応じてクエリ結果を絞り込みまたは拡張することができます。
MDEXエンジンは、適切な次のステップ絞り込みオプションを提供することにより、”結果が見つかりません”などの行き止まりを防ぐように検索結果を計算
これはEndecaを他の検索ソリューションと区別する重要な機能です。
2種類の問合せ
Oracle Endeca Searchでは、ナビゲーション・クエリとキーワード検索クエリの2種類の検索問合せがサポートされています。
- ナビゲーションクエリは、アプリケーション定義のレコード特性(オンラインラップトップストアのラップトップの種類や地域など)に基づいて一連のレコー
- キーワード検索クエリは、ユーザー定義のキーワードと後続のクエリ情報に基づいて一連のレコードを返します。
ナビゲーションクエリとキーワード検索クエリは相補的です。 実際、キーワード検索クエリは特別な種類のナビゲーションクエリであり、2つのクエリの結果のデータ構造は同じです: レコードと後続のクエリ情報のセット。
ユーザーは、ナビゲーションクエリとキーワード検索クエリの組み合わせを実行して、目的のレコードセットに最適な方法で移動できます。 たとえば、ユーザーはキーワード検索クエリを実行して一連のレコードを取得し、後続のナビゲーションクエリを使用してそのレコードセットを絞り込むことがで 逆の状況も有効です。
Endecaレコードとは何ですか
Endecaレコードには、ユーザーが移動または検索するデータが含まれています。
Endecaレコードは、ソースデータベース内の従来のレコードに基づいています。 ソースデータベースレコードには、通常、ワインストアのワインボトル、CRMアプリケーションの顧客レコード、ファンド評価者の投資信託などの情報が含まれます。
ソースデータベースレコードは、この情報をプロパティと呼ばれる1つ以上のキー/値のペアに格納します。 この情報は、ソースデータベースレコードをEndecaレコードに変換すると、アプリケーションで使用できるようになります。 ソースデータベースレコードをEndecaレコードに変換するには、ソースレコードプロパティをEndecaレコードのプロパティにマップする必要があります。
したがって、dimensionsとEndecaレコードはソースデータベースレコードのプロパティに対応します。 ソースレコードプロパティと同様に、Endecaプロパティはキー/値のペアです。 次の図は、単純なEndecaレコードのキーと値のペアを示しています:
 単一のEndecaレコードは、任意の数のソースレコードに対応できます。 たとえば、4つの異なるソースレコードが同じ書籍を異なる形式で参照しているとします: ハードカバー、ペーパーバック、大きい印刷物および音声。 ガイド付き検索アプリケーションを構成して、これらの4つのソースレコードの情報を1つのEndecaレコードに結合できます。
単一のEndecaレコードは、任意の数のソースレコードに対応できます。 たとえば、4つの異なるソースレコードが同じ書籍を異なる形式で参照しているとします: ハードカバー、ペーパーバック、大きい印刷物および音声。 ガイド付き検索アプリケーションを構成して、これらの4つのソースレコードの情報を1つのEndecaレコードに結合できます。
Endecaディメンションとディメンション値とは何ですか
ディメンションは、Endecaレコードを構造に整理して、顧客が購入したい製品やサービスに関する情報を検索できるようにする論理的なカテゴリです。
ディメンションは、ディメンション値の階層です。 ディメンション全体は、通常、製品またはサービスの一般的なカテゴリに対応します。 ディメンション値には、製品とサービスに関する詳細な情報がますます含まれており、階層内の下位にあります。
ディメンションの最上位のディメンション値は、ディメンションルートと呼ばれます。 次元ルートは、その次元の名前として機能します。 各軸値には1つ以上の子軸値を含めることができ、子軸値を持つ軸値は親軸値と呼ばれます。
子ディメンション値は、親ディメンション値を1つだけ持つことができます。 同じ親ディメンション値の子であるディメンション値は、兄弟ディメンション値と呼ばれます。 兄弟軸の値は同一にすることはできません。 ただし、兄弟ではない軸値は、同じ軸内であっても同一にすることができます。
子を持たない軸の値は、葉の軸の値と呼ばれます。 通常、リーフ分析コード値には、特定の製品およびサービスに関する情報が含まれます。 たとえば、非リーフディメンション値は価格の範囲を表し、リーフディメンション値の子は価格がその範囲内にある個々の製品を表す場合があります。 次の図は、”Wine Type”という名前の単純なディメンションを示しています。
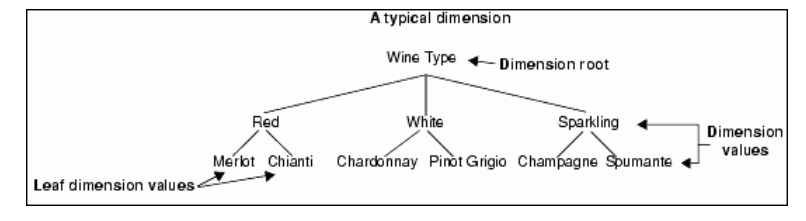
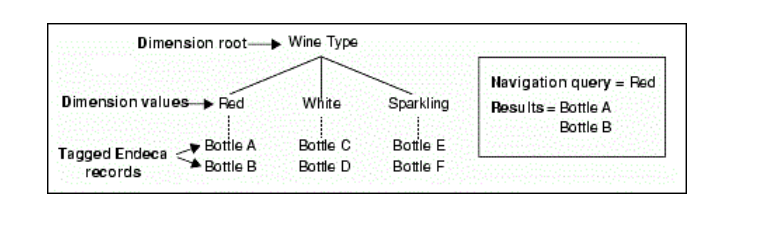
レコードは、ディメンション値でタグ付けすることで、検索可能な階層に整理できます。 レコードには通常、葉軸の値がタグ付けされますが、特別な目的で葉軸以外の値をタグ付けすることができます。
ディメンション値を持つレコードにタグを付けると、次のことが実行されます:
- 関連付けられたディメンション内のレコードの位置を指定します。 以下の例では、ボトルAとBのEndecaレコードにWineタイプの寸法の赤の寸法値がタグ付けされ、ボトルCとDのEndecaレコードに白の寸法値がタグ付けされます。
- ナビゲーションクエリでそのディメンション値が選択されている場合、レコードを有効な結果として識別します。
Endeca searchのベストプラクティス-
検索エンジンには、車のような通常のメンテナンスが必要です。
- 正確な検索結果–
- Endecaがゼロの結果を報告した毎日の検索キーワードのリストを生成します。 このリストは、Endeca engineの要求ログから抽出できます。
- すべてのテキストフィールドを既存のEndecaの検索インターフェイスの一部にせずに検索可能にします。 検索インターフェイスの一部ではないフィールド/ディメンションのみが検索され、インデックスが作成されていても検索に参加することはありません。
- すべての検索可能なテキストフィールドに対して検証するために、特定した結果がゼロになった検索用語を使用します。
- テキストフィールドと検索インターフェイスの間の結果カウントの不一致を示すレポートを生成する–検索インターフェイスが結果を返さず、個々のテキ
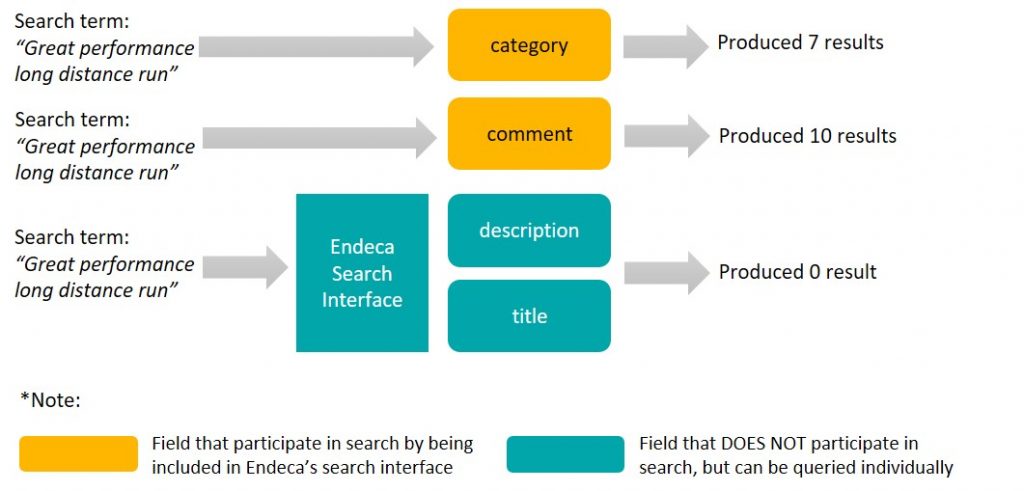
- 次の表は、上記のステップの出力を記録しています。 本当にゼロの結果を生成しなかったすべての検索用語(列1)(列5)については、さらなる分析とアクションが必要です。 これらの検索用語は、実際にはゼロの結果を生成していることになっていませんでした。
- 次の表は、上記のステップの出力を記録しています。 本当にゼロの結果を生成しなかったすべての検索用語(列1)(列5)については、さらなる分析とアクションが必要です。 これらの検索用語は、実際にはゼロの結果を生成していることになっていませんでした。
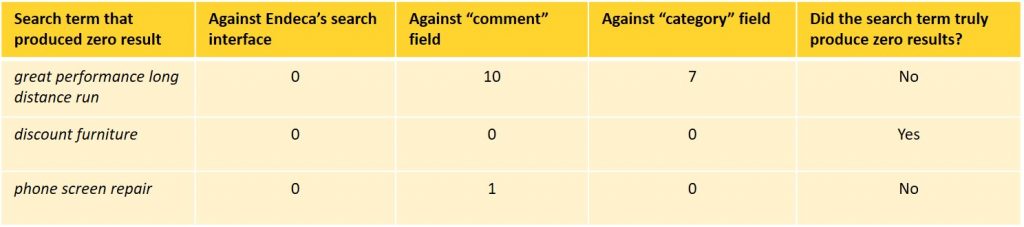
- 上記の調査結果に基づいて、次のいずれかのアプローチを使用して問題を解決できます:
- 結果を返したテキストフィールドを既存の検索インターフェイスに追加するか、
- 結果を返したテキストフィールドの値を検索インターフェイスの既存
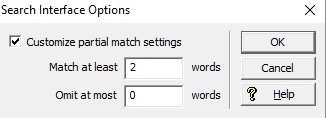
さらに、部分一致構成はゼロヒットシナリオにも寄与する可能性があります。 ユーザーが家電サイトで”強力な食器洗い機”と”静かな冷蔵庫”を検索するケースを考えてみましょう。 デフォルトのEndeca partial match設定では、結果は少なくとも2つの単語に一致する必要があります(下のスクリーンショットを参照)。これにより、2つのキーワードを含むすべての検索語が「すべてのキーワードに一致する」に効果的に変換されます。 その結果、小売業者のwebサイトに製品の説明やタイトルに「強力」または「静か」が含まれていない場合、ユーザーの検索結果ページに冷蔵庫や食器洗い機は表示さ 小売業者は、ゼロヒット率を減らすために、部分一致を”少なくとも1つの単語に一致させる”ように調整することを検討することができます。
- 効率的な検索結果-Endecaは、エンジンキャッシュを使用して、以前の要求で既に処理された結果を格納します。これは、同じ要求を繰り返し処理することを回避するため、検索パフォーマンスを向上させるのに役立ちます。 エンジンキャッシュを活用してパフォーマンスを向上させることは有利ですが、考慮すべき点がいくつかあります。
- エンジン要求ログから結果をキャッ これらのクエリは、エンジンをウォームアップするために使用されます。 たとえば、Endecaを搭載したトップナビゲーションメニュー項目は、一般的にすべてのページで共通しています。 これは、すべての要求に対してエンジンを押すのではなく、キャッシュされた結果の良い候補です。 キャッシングのもう一つの良い候補は、人気のある検索クエリです。 たとえば、家電量販店やデパートの場合、一般的な休日検索クエリには、”Xbox”、”Amazon Echo”、”black Friday deals”などがあります。”
- エンジンのキャッシュメモリは、キャッシュされた結果を保持するのに十分な大きさでなければなりません。
- エンジンキャッシュは、ベースラインの更新(インデックスの完全な更新)のたびに検証され、その時点で、上記で特定したクエリを使用してキャッシュを移入(暖め)する必要があります。
- 検索の関連性-Endeca検索の関連性は、
- Endeca search interface–インデックス内の各レコードから検索可能なフィールドのリストで構成されます。 検索インターフェイスに含まれる検索可能なフィールドが多いほど、検索が広くなります。 反対の結果は狭い検索になります。
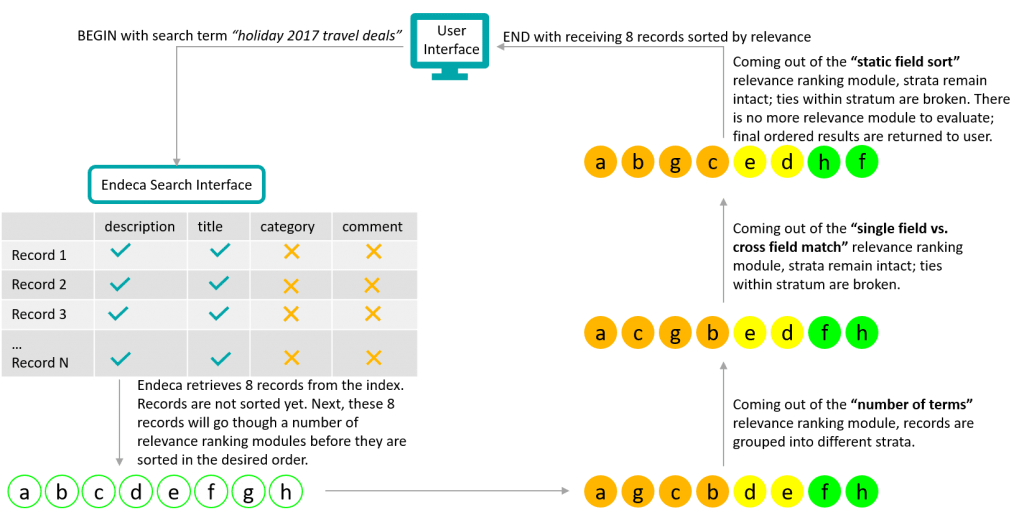
- 関連性ランキングモジュール–次々に配置されたときに、目的のランキング注文を生成するすぐに使用できるランキングアルゴリズム。 最も頻繁に使用されるモジュールは次のとおりです:
-
- 用語の数-一致した用語の数に基づいて結果をランク付けします。
検索語:”台所の流しが漏れている”
一致レコード:”私の台所の流しは、それを修正した後、もう漏れていない”と”私はまだ私の台所にasinkをまだインストールしていない”
ランキング:レコード1は、三つのキーワードすべてに一致したため、レコード2よりも高いランクにランクされています。
- 単一一致対クロスフィールド一致–すべての検索語の単一フィールド一致は、クロスフィールドに一致したものよりも高いスコアを持っています。
-
検索語:”人気の春休みの目的地”
一致するレコード:
レコード1:
タイトル:”人気の春休みの目的地!”
説明:”割引航空運賃、春休みのホテル…”
レコード2:
タイトル:”春休みの人気は何ですか?”
説明:”これらはみんなの夢の目的地です!”
ランキング: レコード1は、そのタイトルが検索語のすべてのキーワードと一致したため、レコード2よりも上位にランクされます。
- フィールド値で昇順/降順に並べ替えます。 人気は、このアルゴリズムを適用できる良い例です。 次の図は、関連性コンポーネントがどのように連携して目的の順位付け順序を生成するかを示しています。
-
Oracle Endecaの使用量が削減されたのはなぜですか?
オラクルは道を失った。 それは技術曲線の後ろに落ち、デジタル小売の新しい要求に対処するための説得力のあるロードマップを提供することができませんでした。 Endecaはもともと、業界で最も優れたエンジニアによって構築された革新的でオープンなプラットフォームでしたが、長年にわたってOracleはEndecaを機能が制限され、変更が難しく、展開が遅く、保守が高価で、革新することが不可能に近い巨大で剛性のある”ブラックボックス”に変えました。
Endecaの代替品を探しているなら、ExpertrecのEndecaの代替品を見ることができます。

Endeca Alternativeを使用する