Questo articolo è incentrato sull’apprendimento come un nucleo microcontrollore è progettato, ed è destinato solo per uso educativo. Si prega di visitare www.zilog.com e controlla la linea di prodotti del produttore per selezionare un microcontrollore adatto alle tue esigenze di progetto (dai Bis Z8 a otto bit! e eZ80 acclama al 32-bit ARM Cortex-M3 basato ZNEO32! che include funzionalità avanzate di controllo del motore).
La mia storia d’amore con microcontrollori e microprocessori è iniziata nel 1988 quando stavo lavorando per una laurea tecnica presso CEFET-PR (una scuola secondaria/tecnica brasiliana di quattro anni e università situata a Curitiba). Ho iniziato imparando le basi mentre esploravo il classico Zilog Z-80 (Figura 1a).

FIGURA 1A. Lo Zilog Z-80A (per gentile concessione di Wikimedia Commons).
Avanti veloce attraverso una carriera di programmazione che includeva la creazione di alcuni libri sulla programmazione dei microcontrollori (vedi Risorse), l’avvio di una piccola casa di design (ScTec) e la fine di un programma post-laurea presso CEFET-SC (un’altra università brasiliana situata a Florianopolis). Questo è stato nel 2008, quando ho avuto più contatti con la logica programmabile e VHDL e la mia curiosità è stato raggiunto il picco. Anni dopo, nel 2016, ho trovato un kit FPGA (Field-Programmable Gate Array) molto conveniente e ho deciso di dargli una possibilità e ho iniziato a saperne di più sulla tecnologia FPGA.
Cosa c’è di meglio che progettare un softcore per saperne di più su VHDL (VHSIC hardware description language), FPGA e core microprocessori stessi? Ho finito per scegliere un moderno parente Z – 80: lo Zilog Z8 Encore! (alias eZ8; Figura 1b).

FIGURA 1B. Zilog eZ8.
È un core microcontrollore a otto bit con un set di istruzioni semplice ma potente e un debugger on-chip molto bello. Con il suo leggero IDE (integrated Development environment) e il compilatore ANSI C gratuito, è un eccellente progetto per imparare (e anche insegnare) sui sistemi embedded.
Prima di tuffarsi nelle profondità del funzionamento del nucleo, VHDL, e FPGA, diamo uno sguardo sul Zilog Z8 Encore! caratteristica.

FIGURA 1C. FPz8 su un FPGA.
Zilog Z8 Bis!
L’eZ8 è una famiglia di microcontrollori a otto bit basata sulla famiglia Z8 di successo di Zilog e sul grande patrimonio Z-80. È dotato di una macchina Harvard CISC con fino a 4.096 byte di RAM (file register e funzione speciale registra area), fino a 64 KB di memoria di programma (di solito memoria Flash), e fino a 64 KB di memoria dati (RAM). Il core eZ8 include anche un controller di interrupt vectored con priorità programmabile e un debugger su chip che comunica con il computer host utilizzando una comunicazione seriale asincrona. Questi microcontrollori sono dotati di un set di periferiche molto bello, che vanno dai versatili timer a 16 bit ai timer di controllo del motore, da più UART (IrDA ready) a dispositivi USB e molto altro (visita www.zilog.com per controllare la linea di prodotti completa).
Una caratteristica importante del modello di programmazione eZ8 è la mancanza di un accumulatore fisso. Invece, uno qualsiasi dei 4.096 possibili indirizzi RAM può funzionare come accumulatori. La CPU tratta la sua RAM principale (il file e SFRs — special function registers — area) come un grande insieme di registri della CPU. Per ottenere ciò, la RAM è divisa in gruppi di registro (ci sono 256 gruppi di 16 registri di lavoro ciascuno). Un’istruzione di solito funziona all’interno di un singolo gruppo di registri di lavoro, selezionato da un SFR denominato RP (register pointer). Si noti che tutti gli SFRs si trovano nell’ultima pagina della RAM (indirizzi a partire da 0xF00 fino a 0xFFF).
Per quanto riguarda il set di istruzioni, ci sono 83 diverse istruzioni suddivise in due pagine opcode. Comprende istruzioni usuali per operazioni di base come addizione, sottrazione, operazioni logiche, istruzioni di manipolazione dei dati, istruzioni di spostamento, istruzioni di cambiamento di flusso, alcune istruzioni a 16 bit, test e manipolazione dei bit, 8×8 moltiplicare, ecc.
L’area di memoria del programma è organizzata in modo che i primi indirizzi siano dedicati a scopi speciali. Gli indirizzi 0x0000 e 0x0001 sono dedicati alle opzioni di configurazione; gli indirizzi 0x0002 e 0x0003 memorizzano il vettore di reset; e così via. La tabella 1 mostra l’organizzazione della memoria del programma.
| 0x0000 | Option bytes |
| 0x0002 | Reset vector |
| 0x0004 | WDT vector |
| 0x0006 | Illegal instruction vector |
| 0x0008 to 0x0037 | Interrupt vectors |
| 0x0038 to 0xFFFF | User program memory area |
TABLE 1. Simplified program memory organization.
Alcuni dispositivi includono anche un secondo spazio dati (fino a 65.536 indirizzi) a cui è possibile accedere solo utilizzando le istruzioni LDE/LDEI. Questa area può essere utilizzata per memorizzare dati meno utilizzati (poiché la lettura/scrittura su di essa è più lenta dell’area RAM/SFR).
FPz8
La prima implementazione di FPz8 utilizza un approccio di progettazione molto conservativo e cablato con due bus principali: uno per la memoria di programma e un altro per la memoria di registro. Poiché ho scelto di non includere un’area di memoria dati, le istruzioni LDE/LDEI non sono implementate.
I bus di memoria di programma comprendono un instruction address bus (IAB) a 16 bit, un Instruction data bus a otto bit (IDB per la lettura dei dati dalla memoria di programma), un Instruction write data bus a otto bit (IWDB per la scrittura dei dati nella memoria di programma) e un segnale PGM_WR che controlla la scrittura nella memoria di programma. FPz8 include 16.384 byte di memoria di programma implementati utilizzando sincrono blocco RAM (il che significa che il contenuto della memoria di programma viene perso quando il dispositivo è spento).
I cinque bus area di registro comprendono tre per l’area di registro file (RAM utente) e altri due dedicati a registri di funzioni speciali. C’è un bus di indirizzo del registro di file principale a 12 bit (FRAB), un bus di dati di input del registro di file a otto bit (FRIDB), un bus di dati di output del registro di file a otto bit (FRODB), un bus di dati di input del registro di otto bit (RIDB) e infine un bus di dati di L’FPz8 include 2.048 byte di memoria RAM dell’utente implementati utilizzando la RAM a blocchi sincroni.
La figura 2 mostra uno schema a blocchi del FPz8; è possibile vedere la CPU, due unità di memoria (una per l’archiviazione dei programmi e l’altra per l’archiviazione dei dati) e anche un modulo timer esterno.
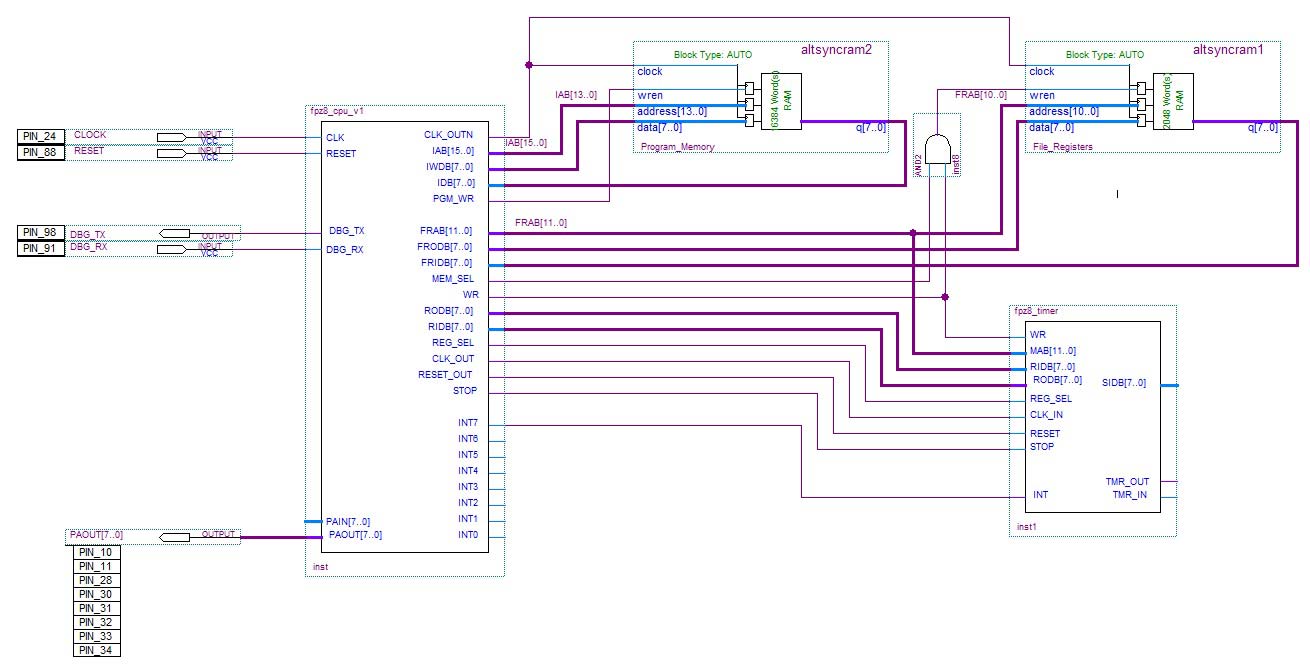
FIGURA 2. Schema a blocchi FPz8.
Si noti che non sto usando bus bidirezionali per qualsiasi interconnessione in questo progetto. I bus unidirezionali sono più semplici da usare, anche se sono meno efficienti in termini di spazio.
La descrizione VHDL di FPz8 è grande e un po ‘ complessa, quindi ho intenzione di dividere il suo funzionamento in alcuni moduli per facilitare la comprensione:
- Instruction queueing engine
- Instruction decoding
- Interrupt processing
- Debugger
Instruction Queueing Engine
Il recupero delle istruzioni è un compito primario per qualsiasi CPU. L’architettura Harvard di FPz8 consente il recupero simultaneo e l’accesso ai dati (grazie a bus separati per istruzioni e dati). Ciò significa che la CPU può recuperare una nuova istruzione mentre un’altra sta leggendo o scrivendo nella memoria dati.
L’eZ8 ha una parola di istruzioni di lunghezza variabile (la lunghezza delle istruzioni varia da un byte fino a cinque byte); alcune istruzioni sono lunghe ma corrono più velocemente di altre. In questo modo, un’istruzione BRK ha una lunghezza di un byte e viene eseguita in due cicli,mentre un LDX IM, ER1 è lungo quattro byte e viene eseguito in due cicli di clock.
Quindi, come possiamo decodificare con successo tutte queste istruzioni? Con una coda di istruzioni; cioè, un meccanismo che continua a recuperare byte dalla memoria del programma e memorizzarli in un array di otto byte:
if (CAN_FETCH=’1′) then
if (IQUEUE.Il nostro sito utilizza cookie tecnici e di terze parti per migliorare la tua esperienza di navigazione.WRPOS: = 0;
IQUEUE.RDPO: = 0;
IQUEUE.CNT := 0;
IQUEUE.FETCH_STATE: = F_READ;
altro
se (IQUEUE.FULL= ‘0’) quindi
IQUEUE.CODA(IQUEUE.WRPOS) := IDB;
FETCH_ADDR := FETCH_ADDR + 1;
IAB <= FETCH_ADDR;
IQUEUE.RRPOS: = IQUEUE.WRPOS + 1;
IQUEUE.NT: = IQUEUE.CNT + 1;
fine se;
fine se;
fine se;
se (IQUEUE.CNT=7) quindi IQUEUE.PIENO:= ‘1’; altro IQUEUE.PIENO:= ‘0’;
fine se;
ELENCO 1. Motore coda di istruzioni.
Il recupero è controllato da un segnale di abilitazione principale (CAN_FETCH) che può essere disabilitato in alcuni casi speciali (elaborazione di interrupt, istruzioni LDC/LDCI o accesso debugger). Esiste anche una struttura (IQUEUE) che memorizza diversi parametri interni (stato di recupero, puntatori di lettura e scrittura, array di code stesso, un contatore e un indicatore completo).
Il contatore della coda (CNT) viene utilizzato per identificare il numero di byte disponibili per l’uso (lettura) nella coda. La fase decoder utilizza questo numero per verificare che il numero desiderato di byte per l’istruzione sia già disponibile nella coda.
Decodifica delle istruzioni
Questo è dove accade la magia reale. Il decodificatore di istruzioni legge gli opcode dalla coda di istruzioni e li traduce in operazioni corrispondenti.
Progettazione decoder istruzioni iniziato da capire la relazione tra tutte le istruzioni e le modalità di indirizzamento. A prima vista, è facile vedere che alcune istruzioni (Figura 3) sono raggruppate per colonna (DJNZ, JR cc,X, LD r1,IM, JP cc,DA e INC r1). La decodifica di un’istruzione INC r1 è semplice: su queste istruzioni a byte singolo, il nibble alto specifica il registro di origine / destinazione e il nibble inferiore specifica l’istruzione stessa (0xE).
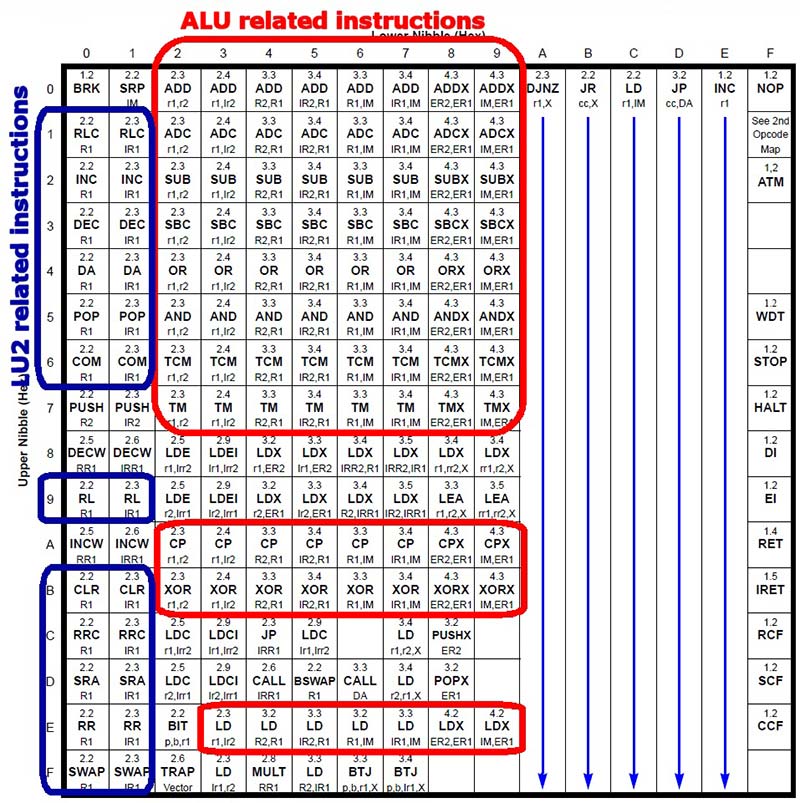
FIGURA 3. Codici operativi per gruppi.
La maggior parte delle istruzioni può essere classificata in base ad alcune regole di base:
- Le colonne (il bocconcino inferiore di un opcode) di solito specificano una modalità di indirizzamento: Le istruzioni della colonna 0x9,ad esempio, utilizzano principalmente la modalità di indirizzamento IM, ER1 e sono lunghe quattro byte (il secondo byte è l’operando immediato e gli ultimi due byte sono l’indirizzo esteso di destinazione).
- Le righe (il bocconcino più alto di un opcode) di solito specificano un’operazione: le istruzioni della riga 0x0 sono per lo più operazioni di aggiunta; le istruzioni della riga 0x2 sono per lo più operazioni di sottrazione e così via.
Se guardiamo alla riga 0x1, possiamo vedere che le colonne 0x0 e 0x1 sono istruzioni RLC e le colonne 0x2 fino a 0x9 sono istruzioni ADC. Quindi, possiamo progettare un ALU che prende un bocconcino come input (il bocconcino più alto dall’opcode) e lo decodifica di conseguenza. Mentre questo funzionerebbe per le colonne da 0x2 a 0x9, avremmo bisogno di un altro approccio per le prime due colonne.
Ecco perché ho finito per scrivere due unità: una ALU che si concentra sulla maggior parte delle istruzioni aritmetiche e logiche; e una seconda unità (Unità logica 2 o LU2) che esegue altre operazioni mostrate nelle colonne 0x0 e 0x1 (non tutte le operazioni viste su quelle colonne sono eseguite da LU2). I codici operativi sia per ALU che per LU2 sono stati scelti per corrispondere alle righe opcode mostrate in Figura 3.
Un altro dettaglio importante è che tutte le istruzioni all’interno della stessa colonna e gruppo hanno la stessa dimensione in byte, quindi possono essere decodificate nella stessa sezione decoder.
Il design del decodificatore fa uso di una grande macchina a stati finiti (FSM) che avanza su ogni tick di clock. Ogni istruzione inizia nella stat CPU_DECOD. È qui che il decodificatore decodifica effettivamente gli opcode, prepara i bus e i segnali di supporto interni e passa ad altri stati di esecuzione. Tra tutti questi stati, due sono ampiamente utilizzati da molte istruzioni: CPU_OMA e CPU_OMA2. Riesci a indovinare perché? Se hai detto perché sono legati a ALU e LU2, hai assolutamente ragione!
OMA è l’abbreviazione di One Memory Access ed è l’ultimo stato per tutte le istruzioni relative all’ALU (ADD, ADC, ADDX, ADCX, SUB, SBC, SUBX, SBCX, OR, ORX, ANDX, XOR, XORX, CP, CPC, TCM, TCMX, TM, TMX e alcune varianti di LD e LDX). D’altra parte, CPU_OMA2 è l’ultimo stato per tutte le istruzioni relative a LU2 (RLC, INC, DEC, DA, COM, RL, CLR, RRC, SRA, SRL, RR e SWAP).
Ora, diamo un’occhiata all’interno dello stato CPU_DECOD. Fare riferimento alla Figura 4.
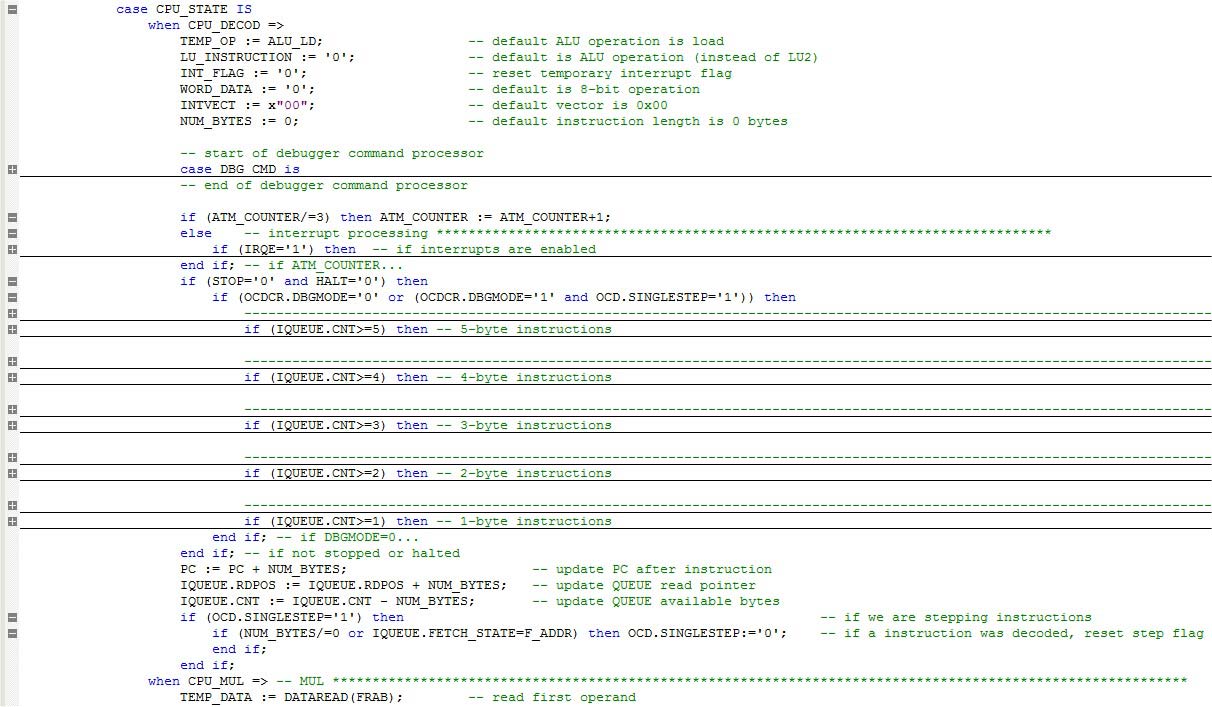
FIGURA 4. Stato CPU_DECOD.
All’interno dello stato CPU_DECOD, possiamo vedere che si svolge molta azione. All’inizio, alcune variabili temporanee vengono inizializzate a una condizione predefinita. Si noti che NUM_BYTES è molto importante in quanto controlla quanti byte sono stati consumati dal decodificatore di istruzioni. Il suo valore viene utilizzato nell’ultima parte di questa fase per incrementare il PC (program counter), far avanzare il puntatore di lettura della coda e diminuire il numero di byte disponibili nella coda.
Seguendo la sezione di inizializzazione, possiamo vedere la sezione di elaborazione degli interrupt. È responsabile del rilevamento di eventuali interrupt in sospeso e prepara la CPU di conseguenza. Ne parlerò nella prossima sezione.
Il blocco di decodifica delle istruzioni effettive controlla se una modalità a basso consumo non è attiva e anche se la modalità debugger è disattivata (OCDCR.DBGMODE=0). Oppure, mentre in modalità debug, è stato emesso un comando di debug a singolo passaggio (OCDCR.DBGMODE=1 e OCD.SINGLE_STEP=1). Quindi controlla i byte disponibili nella coda e procede con la decodifica.
Alcune istruzioni (principalmente quelle singlebyte) sono completate all’interno dello stato CPU_DECOD, mentre altre hanno bisogno di più stati fino a quando non sono completamente completate.
Si noti che alcune istruzioni di decodifica può fare uso di diverse funzioni e procedure scritte appositamente per il FPz8:
- DATAWRITE-Questa procedura prepara gli autobus per un’operazione di scrittura. Seleziona se la destinazione è un SFR interno, un SFR esterno o una posizione RAM dell’utente.
- DATAREAD-Questa è una funzione reciproca per DATAWRITE. Viene utilizzato per leggere un indirizzo di origine e sceglie automaticamente se si tratta di un SFR interno, un SFR esterno o di una posizione RAM dell’utente.
- CONDITIONCODE-Utilizzato per istruzioni condizionali (come JR e JP). Richiede un codice di condizione a quattro bit, lo verifica e restituisce il risultato.
- INDIRIZZO4, INDIRIZZO8 e INDIRIZZO12: queste funzioni restituiscono un indirizzo a 12 bit da un’origine a quattro, otto o 12 bit. Usano il contenuto del registro RP per generare l’indirizzo finale a 12 bit. ADDRESSER8 e ADDRESSER12 controllano anche qualsiasi modalità di indirizzamento con escape.
- ADDER16-Si tratta di un adder a 16 bit per il calcolo dell’offset dell’indirizzo. Richiede un operando firmato a otto bit, sign lo estende, lo aggiunge all’indirizzo a 16 bit e restituisce il risultato.
- ALU e LU2-Questi sono stati discussi in precedenza, ed eseguire la maggior parte delle operazioni aritmetiche e logiche.
Interrupt Processing
Come ho detto prima, eZ8 ha un controller di interrupt vectored con priorità programmabile. All’inizio, ho pensato che questa sezione non sarebbe stata così difficile perché gli interrupt non sono un grosso problema, giusto? Bene, quando ho iniziato a capire come eseguire tutte le attività necessarie (salvataggio del contesto, vectoring, gestione delle priorità, ecc.), ho capito che sarebbe stato più difficile di quanto pensassi. Dopo un paio d’ore, mi è venuto in mente il design attuale.
Il sistema di interrupt di FPz8 ha finito per essere semplice. Ha otto ingressi (da INT0 a INT7); un interrupt globale (bit IRQE situato nel registro IRQCTL); due registri per l’impostazione della priorità (IRQ0ENH e IRQ0ENL); e un registro per i flag di interrupt (IRQ0). Il design utilizza una catena IF nidificata che genera un indirizzo vettoriale al rilevamento di un evento di interrupt relativo a un interrupt abilitato.
La figura 5 mostra una visualizzazione compressa del sistema di interrupt. Nota c’è una prima istruzione IF con un simbolo ATM_COUNTER. Questo è un semplice contatore utilizzato dall’istruzione ATM (disabilita gli interrupt per tre cicli di istruzioni, consentendo operazioni atomiche).
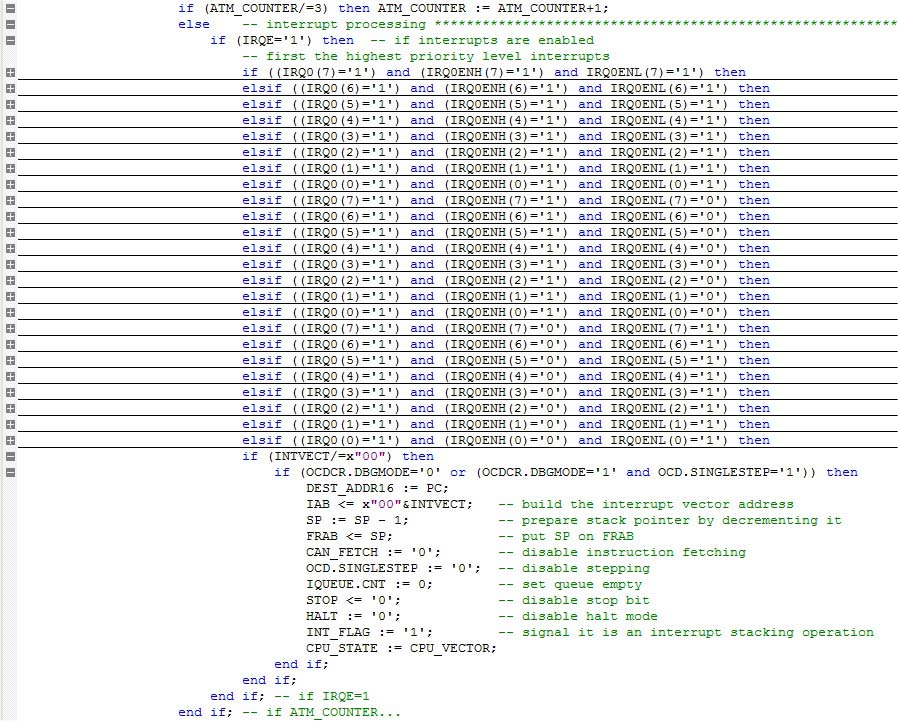
FIGURA 5. Sistema di interruzione FPz8.
Un ultimo commento riguardante gli interrupt: I campioni di interrupt Flag Register (IRQ0) interrompono ogni fronte di salita dell’orologio di sistema. Ci sono anche due variabili buffer (IRQ0_LATCH e OLD_IRQ0) che memorizzano lo stato corrente e l’ultimo dei flag. Ciò consente il rilevamento dei bordi di interrupt e sincronizza anche gli ingressi esterni all’orologio interno (gli FPGA non funzionano bene con segnali interni asincroni).
On-Chip Debugger
Questa è probabilmente la caratteristica più cool di questo softcore in quanto consente un ambiente di sviluppo integrato commerciale (IDE; come ZDS-II di Zilog) per comunicare, programmare ed eseguire il debug del software in esecuzione su FPz8. Il debugger on-chip (OCD) è composto da un UART con capacità autobaud e un processore di comando collegato ad esso. L’UART esegue la comunicazione seriale con un PC host e fornisce comandi e dati alla macchina a stati debugger che elabora i comandi di debug (il comando debugger processing FSM si trova all’interno dello stato CPU_DECOD).

FIGURA 6. On-chip debugger UART (notare il sincronizzatore DBG_RX).
Il mio design OCD implementa quasi tutti i comandi disponibili sull’hardware reale, ad eccezione di quelli relativi alla memoria dati (comandi di debug 0x0C e 0x0D); il contatore di runtime di lettura (0x3); e la memoria del programma di lettura CRC (0x0E).
Una cosa che vorrei evidenziare è la cura è necessaria quando si tratta di segnali asincroni all’interno di FPGA. Il mio primo progetto non ha tenuto conto di ciò durante l’elaborazione del segnale di ingresso DBG_RX. Il risultato è stato assolutamente strano. Il mio progetto aveva funzionato perfettamente nella simulazione. L’ho scaricato su un FPGA e ho iniziato a giocare con l’interfaccia seriale di debug utilizzando un terminale seriale (la mia scheda FPGA ha un convertitore seriale-USB incorporato).
Con mia sorpresa, mentre la maggior parte delle volte potevo inviare con successo comandi e ricevere i risultati attesi, a volte il design semplicemente si bloccava e smetteva di rispondere. Un soft reset farebbe tornare le cose al loro corretto funzionamento, ma questo mi intrigava. Cosa stava succedendo?
Dopo molti test e alcuni Googling, ho capito che era probabilmente correlato ai bordi asincroni del segnale di ingresso seriale. Ho quindi incluso un latch a cascata per sincronizzare il segnale con il mio orologio interno e tutti i problemi erano spariti! Questo è un modo difficile per imparare che devi sempre sincronizzare i segnali esterni prima di alimentarli in una logica complessa!
Devo dire che il debug e la raffinazione del codice debugger è stata la parte più difficile di questo progetto; soprattutto perché interagisce con tutti gli altri sottosistemi inclusi i bus, il decoder e la coda di istruzioni.
Sintetizzare e testare
Una volta compilato completamente (ho usato Quartus II v9.1 sp2), il core FPz8 ha utilizzato 4.900 elementi logici, 523 registri, 147.456 bit di memoria su chip e un moltiplicatore a nove bit incorporato. Nel complesso, l’FPz8 utilizza l ‘ 80% delle risorse disponibili dell’EP4CE6. Anche se questo è molto, ci sono ancora alcuni elementi logici 1,200 disponibili per le periferiche (il mio semplice timer a 16 bit aggiunge circa 120 elementi logici e 61 registri). Si adatta anche al più piccolo Cyclone IV FPGA — l’EP4CE6 — che è quello montato sulla scheda mini low cost che ho usato qui (Figura 7).

FIGURA 7. Altera Cyclone IV EP4CE6 mini bordo.
Le caratteristiche mini board (insieme al dispositivo EP4CE6): una memoria di configurazione seriale EPCS4 (montata sul lato inferiore); un chip convertitore seriale-USB FTDI e un modulo oscillatore a cristallo da 50 MHz; alcuni pulsanti; LED; e intestazioni dei pin per accedere ai pin FPGA. Non c’è un USB-Blaster integrato (per la programmazione FPGA), ma il pacchetto che ho comprato includeva anche un dongle di programmazione esterno.
Per quanto riguarda i test del mondo reale, inutile dire che l’FPz8 non ha funzionato la prima volta! Dopo aver pensato un po ‘ e letto i messaggi di output del compilatore, ho capito che probabilmente si trattava di un problema di temporizzazione. Questo è un dilemma molto comune quando si progetta con logica programmabile, ma poiché questo era il mio secondo progetto FPGA di sempre, non ho prestato abbastanza attenzione ad esso.
Controllando i messaggi di analisi dei tempi, ho potuto vedere un avvertimento che il clock massimo dovrebbe essere di circa 24 MHz. All’inizio, ho provato a utilizzare un divisore per 2 per generare un clock della CPU a 25 MHz, ma non era affidabile. Ho quindi usato un divisore per 3. Tutto ha iniziato a funzionare perfettamente!
Ecco perché FPz8 attualmente funziona a 16.666 MHz. È possibile ottenere velocità più elevate utilizzando uno dei PLL interni per moltiplicare/dividere l’orologio principale al fine di ottenere un clock risultante inferiore a 24 MHz, ma superiore a 16,666 MHz.
La programmazione e il debug
L’utilizzo di FPz8 è molto semplice e diretto. Una volta scaricato il progetto nell’FPGA, la CPU inizierà a eseguire qualsiasi programma caricato in memoria. È possibile fornire un file esadecimale e utilizzare il Plug-in Manager MegaWizard per modificare il file di inizializzazione della memoria del programma. In questo modo, il codice dell’applicazione inizierà a funzionare dopo un segnale di reset.
È possibile utilizzare l’IDE Zilog ZDS-II per scrivere codice Assembly o C e generare i file esadecimali necessari (di solito seleziono lo Z8F1622 come dispositivo di destinazione in quanto ha anche 2 KB di RAM e 16 KB di memoria di programma). Grazie al debugger on-chip, è anche possibile utilizzare l’IDE ZDS-II per scaricare il codice sull’FPz8 utilizzando una connessione di debug seriale (USB, nel nostro caso).
Prima di connettersi, assicurarsi che le impostazioni del debugger siano le stesse della Figura 8. Deseleziona l’opzione” Usa cancella pagina prima di lampeggiare “e seleziona” SerialSmartCable ” come strumento di debug corrente. Non dimenticare di controllare anche se la porta COM virtuale di FTDI è correttamente selezionata come porta di debug (usa il pulsante Setup). È possibile impostare anche la velocità di comunicazione desiderata; 115.200 bps funziona molto bene per me.
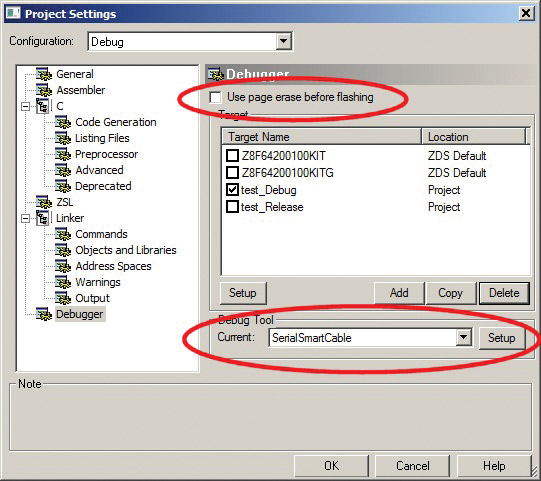
FIGURA 8. Impostazioni del debugger.
Si noti che durante la connessione a FPz8, l’IDE ZDS-II mostrerà un messaggio di avviso che informa che il dispositivo di destinazione non è lo stesso del progetto. Ciò accade perché non ho implementato alcune aree di memoria ID. Basta ignorare l’avviso e procedere con la sessione di debug.
Una volta scaricato il codice, è possibile avviare l’applicazione (pulsante VAI), istruzioni passo, ispezionare o modificare i registri, impostare i punti di interruzione, ecc. Come con qualsiasi altro buon debugger, è possibile, ad esempio, selezionare il registro PAOUT (in gruppo PORTE) e persino modificare lo stato dei LED collegati a PAOUT.
Alcuni semplici esempi di codice C possono essere trovati nei download.
Tieni presente che FPz8 ha una memoria di programma volatile. Pertanto, qualsiasi programma scaricato su di esso viene perso quando l’FPGA viene spento.
Chiusura
Questo progetto mi ha richiesto un paio di settimane per essere completato, ma è stato piacevole ricercare e progettare un core del microcontrollore.
Spero che questo progetto possa essere utile per chiunque voglia conoscere le basi dell’informatica, i microcontrollori, la programmazione embedded e/o VHDL. Credo che — se abbinato a una scheda FPGA a basso costo-l’FPz8 possa fornire un fantastico strumento di apprendimento (e insegnamento). Divertiti! NV
CEFET-PR:
www.utfpr.edu.br
ScTec:
www.sctec.com.br
HCS08 scatenato:
https://www.amazon.com/HCS08-Unleashed-Designers-Guide-Microcontrollers/dp/1419685929
Zilog eZ8 Manuale della CPU (UM0128):
www.zilog.com/docs/UM0128.pdf
Zilog Z8F64xx Product Specification (PS0199):
www.zilog.com/docs/z8encore/PS0199.pdf
Zilog ZDS II IDE User Manual (UM0130):
www.zilog.com/docs/devtools/UM0130.pdf
Zilog ZDS-II Software Download:
https://www.zilog.com/index.php?option=com_zcm&task=view&soft_id=7&Itemid=74
Zilog Microcontroller Product Line:
http://zilog.com/index.php?option=com_product&task=product&businessLine=1&id=2&parent_id=2&Itemid=56
Project Files available at:
https://github.com/fabiopjve/VHDL/tree/master/FPz8
FPz8 at Opencores.org:
http://opencores.org/project,fpz8