Di Moritz Mueller-Freitag, Eleven Strategy.
La “irragionevole efficacia” dei dati per le applicazioni di apprendimento automatico è stata ampiamente discussa nel corso degli anni (vedi qui, qui e qui). È stato anche suggerito che molte importanti scoperte nel campo dell’Intelligenza artificiale non sono state vincolate dai progressi algoritmici ma dalla disponibilità di set di dati di alta qualità (vedi qui). Il filo conduttore che attraversa queste discussioni è che i dati sono una componente vitale nel fare state-of-the-art machine learning.
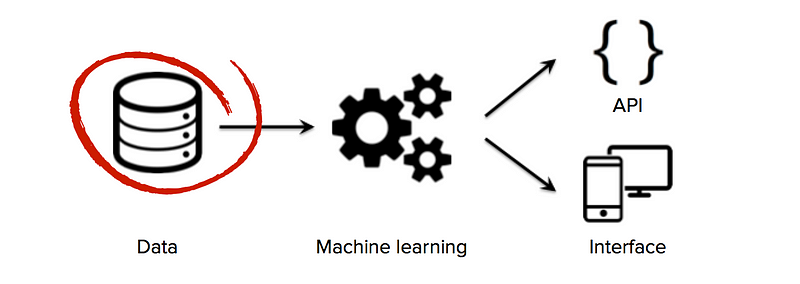
L’accesso a dati di formazione di alta qualità è fondamentale per le startup che utilizzano l’apprendimento automatico come tecnologia di base della propria attività. Mentre molti algoritmi e strumenti software sono open source e condivisi in tutta la comunità di ricerca, i buoni set di dati sono solitamente proprietari e difficili da costruire. Possedere un set di dati ampio e specifico del dominio può quindi diventare una fonte significativa di vantaggio competitivo, specialmente se le startup possono avviare gli effetti della rete di dati (una situazione in cui più utenti → più dati → algoritmi più intelligenti → prodotto migliore → più utenti).
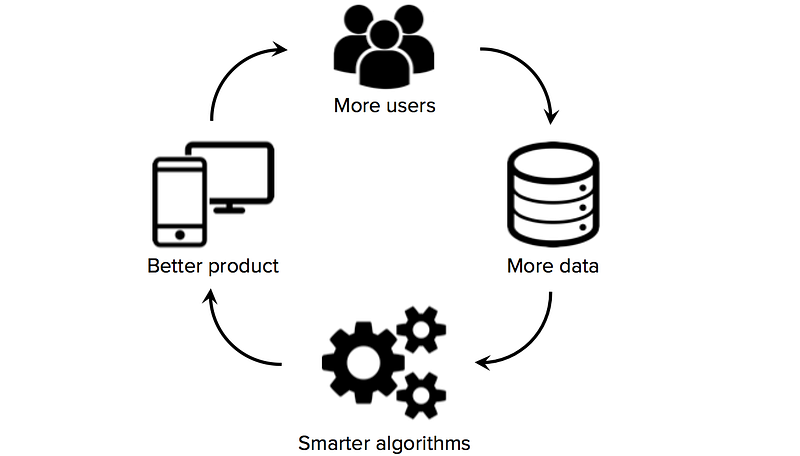
Di conseguenza, una delle decisioni strategiche chiave che le startup di apprendimento automatico devono prendere è come costruire set di dati di alta qualità per addestrare i loro algoritmi di apprendimento. Sfortunatamente, le startup spesso hanno dati limitati o non etichettati all’inizio, una situazione che preclude ai fondatori di fare progressi significativi nella creazione di un prodotto basato sui dati. Vale quindi la pena esplorare le strategie di acquisizione dati fin dall’inizio, prima di assumere il team di data science o costruire una costosa infrastruttura di base.
Le startup possono superare il problema dell’avvio a freddo dell’acquisizione dei dati in numerosi modi. La scelta della strategia/fonte dei dati di solito va di pari passo con la scelta del modello di business, il focus di una startup(consumatore o impresa, orizzontale o verticale, ecc.) e la situazione dei finanziamenti. Il seguente elenco di strategie, sebbene non esaustivo né mutuamente esclusivo, dà un senso per l’ampia gamma di approcci disponibili.
Strategia #1: Lavoro manuale
Costruire un buon set di dati proprietario da zero significa quasi sempre mettere un sacco di up-front, sforzo umano in acquisizione dei dati e l’esecuzione di attività manuali che non scala. Esempi di startup che hanno usato la forza bruta all’inizio sono abbondanti. Ad esempio, molte startup di chatbot impiegano “AI trainer” umani che creano o verificano manualmente le previsioni fatte dai loro agenti virtuali (con vari gradi di successo e un alto tasso di turnover dei dipendenti). Anche i giganti tecnologici ricorrono a questa strategia: tutte le risposte di Facebook M sono riviste e modificate da un team di appaltatori.

Utilizzando la forza bruta per etichettare manualmente i punti dati può essere una strategia di successo fino a quando gli effetti di rete di dati calci in un certo punto in modo che gli esseri umani non più scala ad un ritmo uguale con la base di clienti. Non appena il sistema AI sta migliorando abbastanza velocemente, valori anomali non specificati diventano meno frequenti e il numero di esseri umani che eseguono l’etichettatura manuale può essere diminuito o mantenuto costante.
Interessante per: Più o meno ogni avvio di apprendimento automatico
Esempi:
- Molti chatbot startup (tra cui Magic, GoButler, x.ai e Clara)
- MetaMind (raccolte manualmente e con etichetta del set di dati per la classificazione degli alimenti)
- Costruzione di Radar (dipendenti/tirocinanti manualmente etichetta di immagini di edifici)
Strategia #2: Restringere il dominio
la Maggior parte delle startup cercherà di raccogliere i dati direttamente da parte degli utenti. La sfida è convincere i primi ad utilizzare il prodotto prima che i benefici dell’apprendimento automatico entrino completamente in gioco (perché i dati sono necessari in primo luogo per addestrare e mettere a punto gli algoritmi). Un modo per aggirare questo catch-22 è restringere drasticamente il dominio del problema (ed espandere l’ambito in seguito, se necessario). Come dice Chris Dixon: “La quantità di dati di cui hai bisogno è relativa all’ampiezza del problema che stai cercando di risolvere.”
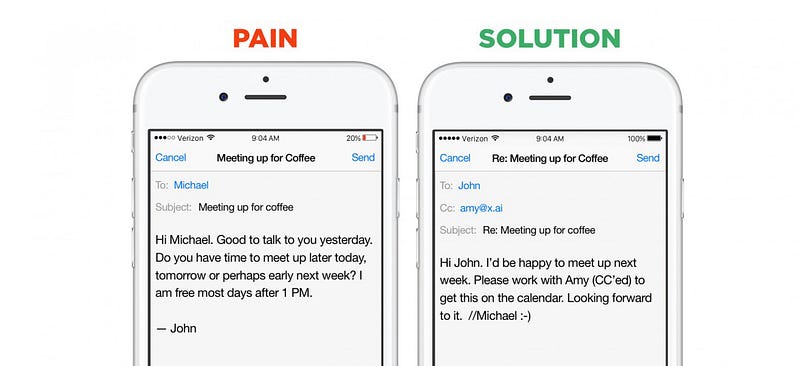
Buoni esempi dei vantaggi di un dominio ristretto sono di nuovo chatbots. Le startup in questo segmento possono scegliere tra due strategie di go-to-market: possono costruire assistenti orizzontali — bot che possono aiutare con un numero molto elevato di domande e richieste immediate (esempi sono Viv, Magic,Awesome, Maluuba e Jam). Oppure possono creare assistenti verticali — bot che cercano di eseguire un lavoro specifico e ben definito estremamente bene (esempi sono x.ai, Clara, DigitalGenius, Kasisto, Meekan — e più recentlyGoButler / Angel. ai). Mentre entrambi gli approcci sono validi, la raccolta dei dati è drammaticamente più facile per le startup che affrontano problemi di dominio chiuso.
Interessante per: imprese Verticalmente integrate
Esempi:
- Altamente specializzato in verticale chatbots (come x.ai, Clara o GoButler)
- Profondità di Genomica (utilizza il deep learning per classificare/interpretare varianti genetiche)
- Quantificato Pelle (utilizza cliente selfies per analizzare pelle di una persona)
Strategia #3: Crowdsourcing / Outsourcing
Invece di utilizzare dipendenti qualificati (o stagisti) per raccogliere manualmente o etichettare i dati, le startup possono anche crowdsourcing il processo. Piattaforme come Amazon Mechanical Turk o CrowdFlower offrono un modo per ripulire i dati disordinati e incompleti utilizzando una forza lavoro online di milioni di persone. Ad esempio, VocalIQ (acquisita da Apple nel 2015) utilizzato Mechanical Turk di Amazon per alimentare il suo assistente digitale migliaia di query degli utenti. I lavoratori possono anche essere esternalizzati impiegando altri appaltatori indipendenti (come fatto da cyClara o Facebook M). La condizione necessaria per l’utilizzo di questo approccio è che l’attività possa essere chiaramente spiegata e non sia troppo lunga/noiosa.

Un’altra tattica è quella di incentivare il pubblico a contribuire volontariamente i dati. Un esempio è Snips, una startup AI con sede a Parigi che utilizza questo approccio per mettere le mani su un certo tipo di dati (e-mail di conferma per ristoranti, hotel e compagnie aeree). Come altre startup, Snips utilizza un sistema gamified in cui gli utenti sono classificati in una classifica.
Interessante per: Utilizzare i casi in cui il controllo di qualità può essere facilmente applicata
Esempi:
- DeepMind, Maluuba, AlchemyAPI e molti altri (vedi qui)
- VocalIQ (usato Mechanical Turk di insegnare il suo programma come le persone parlano)
- Snips (chiede alle persone di contribuire liberamente dati per la ricerca)
Strategia #4: Utente-in-the-loop
Un crowdsourcing strategia che merita la sua categoria è user-in-the-loop.Questo approccio comporta la progettazione di prodotti che forniscono i giusti incentivi per gli utenti a restituire i dati al sistema. Due esempi classici di aziende che hanno utilizzato questo approccio per molti dei loro prodotti sono Google (completamento automatico nella ricerca, Google Translate, filtri antispam, ecc.) e Facebook (utenti che taggano gli amici nelle foto). Gli utenti sono spesso inconsapevoli di fornire queste aziende con i dati etichettati gratuitamente.
Molte startup nello spazio di apprendimento automatico hanno tratto ispirazione da Google e Facebook creando prodotti con UX fault-tolerant che incoraggiano esplicitamente gli utenti a correggere gli errori della macchina. Particolarmente notevoli arere e Duolingo (entrambi fondati da Luis von Ahn). Altri esempi includono Unbabel, Wit.ai e Mapillary.
Interessante per: Consumer-centric startup con costante interazione con l’utente
Esempi:
- Unbabel (comunità di traduttori corretto generata dal computer traduzioni)
- Arguzia.ai (fornito dashboard/API per gli utenti di correggere errori di traduzione)
- Mapillary (gli utenti possono correggere macchina-il traffico generato, segno di rilevamento)
Strategia #5: Side business
Una strategia che sembra essere particolarmente popolare tra le startup di computer vision è quella di offrire un’app mobile gratuita e specifica per il dominio che si rivolge ai consumatori. Clarifai, HyperVerge e Madbits (acquisita da Twitter nel 2014) hanno tutti perseguito questa strategia offrendo app fotografiche che raccolgono dati di immagine aggiuntivi per il loro core business.
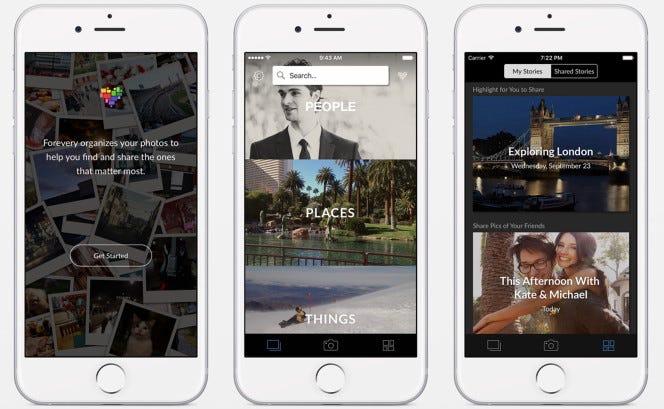
Questa strategia non è completamente priva di rischi (dopo tutto, costa tempo e denaro per sviluppare e promuovere con successo un’app). Le startup devono anche assicurarsi di creare un caso d’uso abbastanza forte che costringa gli utenti a rinunciare ai propri dati, anche se il servizio non ha i vantaggi degli effetti della rete dati all’inizio.
Interessante per: Startup aziendali/piattaforme orizzontali
Esempi:
- Clarifai (Forevery, photo discovery app)
- HyperVerge (Argento, photo organization app)
- Madbits (Momentsia, photo collage app)