Par Moritz Mueller-Freitag, Eleven Strategy.
L' » efficacité déraisonnable » des données pour les applications d’apprentissage automatique a été largement débattue au fil des ans (voir ici, ici et ici). Il a également été suggéré que de nombreuses percées majeures dans le domaine de l’intelligence artificielle n’ont pas été contraintes par les progrès algorithmiques mais par la disponibilité d’ensembles de données de haute qualité (voir ici). Le fil conducteur de ces discussions est que les données sont un élément essentiel de l’apprentissage automatique à la pointe de la technologie.
L’accès à des données de formation de haute qualité est essentiel pour les startups qui utilisent l’apprentissage automatique comme technologie de base de leur entreprise. Alors que de nombreux algorithmes et outils logiciels sont open source et partagés au sein de la communauté de recherche, les bons ensembles de données sont généralement propriétaires et difficiles à construire. Posséder un grand ensemble de données spécifique à un domaine peut donc devenir une source importante d’avantage concurrentiel, en particulier si les startups peuvent relancer les effets de réseau de données (une situation où plus d’utilisateurs → plus de données → algorithmes plus intelligents → meilleur produit → plus d’utilisateurs).
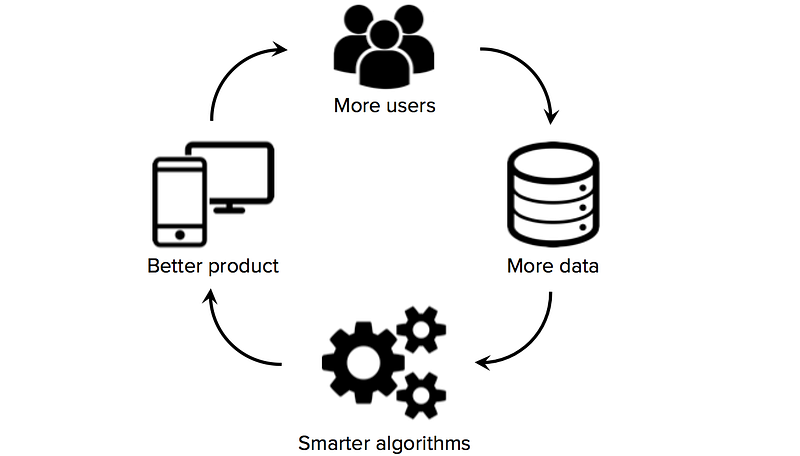
Par conséquent, l’une des décisions stratégiques clés que les startups d’apprentissage automatique doivent prendre est de savoir comment créer des ensembles de données de haute qualité pour entraîner leurs algorithmes d’apprentissage. Malheureusement, les startups ont souvent peu ou pas de données étiquetées au début, une situation qui empêche les fondateurs de faire des progrès significatifs sur la construction d’un produit axé sur les données. Il vaut donc la peine d’explorer les stratégies d’acquisition de données dès le départ, avant d’engager l’équipe de science des données ou de construire une infrastructure de base coûteuse.
Les startups peuvent surmonter le problème du démarrage à froid de l’acquisition de données de nombreuses manières. Le choix de la stratégie/source de données va généralement de pair avec le choix du modèle d’affaires, de l’orientation d’une startup (consommateur ou entreprise, horizontale ou verticale, etc.) et la situation de financement. La liste de stratégies qui suit, bien qu’elle ne soit ni exhaustive ni mutuellement exclusive, donne une idée du large éventail d’approches disponibles.
Stratégie #1: Travail manuel
Construire un bon ensemble de données propriétaire à partir de zéro signifie presque toujours consacrer beaucoup d’efforts humains à l’acquisition de données et à effectuer des tâches manuelles qui ne sont pas évolutives. Les exemples de startups qui ont utilisé la force brute au début sont nombreux. Par exemple, de nombreuses startups de chatbot emploient des « formateurs en IA » humains qui créent ou vérifient manuellement les prédictions faites par leurs agents virtuels (avec plus ou moins de succès et un taux de rotation élevé des employés). Même les géants de la technologie ont recours à cette stratégie: toutes les réponses de Facebook M sont examinées et éditées par une équipe de sous-traitants.

Utiliser la force brute pour étiqueter manuellement les points de données peut être une stratégie réussie tant que les effets de réseau de données interviennent à un moment donné afin que les humains ne s’adaptent plus à un rythme égal à celui de la clientèle. Dès que le système d’IA s’améliore assez rapidement, les valeurs aberrantes non spécifiées deviennent moins fréquentes et le nombre d’humains qui effectuent un étiquetage manuel peut être diminué ou maintenu constant.
Intéressant pour: Plus ou moins chaque démarrage d’apprentissage automatique
Exemples:
- De nombreuses startups de chatbot (y compris Magic, GoButler, x.ai et Clara)
- MetaMind (ensemble de données collectées et étiquetées manuellement pour la classification des aliments)
- Radar de bâtiment (les employés / stagiaires étiquettent manuellement les images des bâtiments)
Stratégie #2: Restreindre le domaine
La plupart des startups essaieront de collecter des données directement auprès des utilisateurs. Le défi consiste à convaincre les premiers utilisateurs d’utiliser le produit avant que les avantages de l’apprentissage automatique ne se concrétisent pleinement (car les données sont nécessaires en premier lieu pour former et affiner les algorithmes). Une façon de contourner ce catch-22 est de réduire considérablement le domaine du problème (et d’élargir la portée plus tard si nécessaire). Comme le dit Chris Dixon: « La quantité de données dont vous avez besoin est relative à l’ampleur du problème que vous essayez de résoudre. »
De bons exemples des avantages d’un domaine étroit sont encore les chatbots. Les startups de ce segment peuvent choisir entre deux stratégies de mise sur le marché: Elles peuvent créer des assistants horizontaux – des robots qui peuvent aider avec un très grand nombre de questions et de demandes immédiates (les exemples sont Viv, Magic, Awesome, Maluuba et Jam). Ou ils peuvent créer des assistants verticaux – des robots qui essaient d’effectuer extrêmement bien un travail spécifique et bien défini (par exemple x.ai , Clara, DigitalGenius, Kasisto, Meekan — et plus récemmentgobutler/Angel.ai). Bien que les deux approches soient valables, la collecte de données est considérablement plus facile pour les startups qui s’attaquent aux problèmes de domaine fermé.
Intéressant pour : Entreprises intégrées verticalement
Exemples:
- Chatbots verticaux hautement spécialisés (tels que x.ai , Clara ou GoButler)
- Génomique profonde (utilise l’apprentissage profond pour classer / interpréter les variantes génétiques)
- Peau quantifiée (utilise des selfies de clients pour analyser la peau d’une personne)
Stratégie #3: Crowdsourcing / Externalisation
Au lieu d’utiliser des employés qualifiés (ou des stagiaires) pour collecter ou étiqueter manuellement les données, les startups peuvent également crowdsourcer le processus. Des plates-formes comme Amazon Mechanical Turk ou CrowdFlower offrent un moyen de nettoyer les données désordonnées et incomplètes en utilisant une main-d’œuvre en ligne de millions de personnes. Par exemple, VocalIQ (acquis par Apple en 2015) a utilisé Mechanical Turk d’Amazon pour alimenter son assistant numérique en milliers de requêtes d’utilisateurs. Les travailleurs peuvent également être externalisés en employant d’autres entrepreneurs indépendants (comme le fait byClara ou Facebook M). La condition nécessaire pour utiliser cette approche est que la tâche puisse être clairement expliquée et ne soit pas trop longue / ennuyeuse.

Une autre tactique consiste à inciter le public à contribuer volontairement aux données. Un exemple est Snips, une start-up d’IA basée à Paris qui utilise cette approche pour mettre la main sur un certain type de données (e-mails de confirmation pour les restaurants, les hôtels et les compagnies aériennes). Comme d’autres startups, Snips utilise un système gamifié où les utilisateurs sont classés dans un classement.
Intéressant pour: Cas d’utilisation où le contrôle de la qualité peut être facilement appliqué
Exemples:
- DeepMind, Maluuba, AlchemyAPI et bien d’autres (voir ici)
- VocalIQ (utilisé Mechanical Turk pour enseigner à son programme comment les gens parlent)
- Snips (demande aux gens de contribuer librement aux données pour la recherche)
Stratégie #4 : User-in-the-loop
Une stratégie de crowdsourcing qui mérite sa propre catégorie est user-in-the-loop.Cette approche consiste à concevoir des produits qui incitent les utilisateurs à restituer des données au système. Deux exemples classiques d’entreprises qui ont utilisé cette approche pour bon nombre de leurs produits sont Google (saisie semi-automatique dans la recherche, Google Translate, filtres anti-spam, etc.) et Facebook (les utilisateurs taguant des amis sur les photos). Les utilisateurs ignorent souvent qu’ils fournissent gratuitement à ces entreprises des données étiquetées.
De nombreuses startups du secteur de l’apprentissage automatique se sont inspirées de Google et de Facebook en créant des produits dotés d’une expérience utilisateur tolérante aux pannes qui encouragent explicitement les utilisateurs à corriger les erreurs de la machine. Arere et Duolingo (tous deux fondés par Luis von Ahn) sont particulièrement remarquables. D’autres exemples incluent Unbabel, Wit.ai et Mapillary.
Intéressant pour: startups centrées sur le consommateur avec une interaction utilisateur constante
Exemples:
- Unbabel (les traducteurs communautaires corrigent les traductions générées par machine)
- Wit.ai (tableau de bord / API fourni aux utilisateurs pour corriger les erreurs de traduction)
- Mapillary (les utilisateurs peuvent corriger la détection des panneaux de signalisation générés par la machine)
Stratégie #5: Side business
Une stratégie qui semble particulièrement populaire parmi les startups de vision par ordinateur consiste à offrir une application mobile gratuite et spécifique à un domaine qui cible les consommateurs. Clarifai, HyperVerge et Madbits (acquis par Twitter en 2014) ont tous poursuivi cette stratégie en proposant des applications photo qui collectent des données d’image supplémentaires pour leur cœur de métier.
Cette stratégie n’est pas totalement sans risque (après tout, cela coûte du temps et de l’argent pour développer et promouvoir avec succès une application). Les startups doivent également s’assurer de créer un cas d’utilisation suffisamment solide qui oblige les utilisateurs à abandonner leurs données, même si le service ne bénéficie pas des effets de réseau de données au début.
Intéressant pour: Startups d’entreprise / plates-formes horizontales
Exemples:
- Clarifai (Forevery, application de découverte de photos)
- HyperVerge (Argent, application d’organisation de photos)
- Madbits (Momentsia, application de collage de photos)