Von Moritz Müller-Freitag, Eleven Strategy.
Die „unzumutbare Effektivität“ von Daten für Machine-Learning-Anwendungen wurde im Laufe der Jahre vielfach diskutiert (siehe hier, hier und hier). Es wurde auch vermutet, dass viele große Durchbrüche auf dem Gebiet der künstlichen Intelligenz nicht durch algorithmische Fortschritte, sondern durch die Verfügbarkeit hochwertiger Datensätze eingeschränkt wurden (siehe hier). Der rote Faden, der sich durch diese Diskussionen zieht, ist, dass Daten eine wichtige Komponente für das hochmoderne maschinelle Lernen sind.
Der Zugang zu qualitativ hochwertigen Trainingsdaten ist für Startups, die maschinelles Lernen als Kerntechnologie ihres Unternehmens nutzen, von entscheidender Bedeutung. Während viele Algorithmen und Softwaretools Open Source sind und von der Forschungsgemeinschaft gemeinsam genutzt werden, sind gute Datensätze in der Regel proprietär und schwer zu erstellen. Der Besitz eines großen, domänenspezifischen Datensatzes kann daher zu einer erheblichen Quelle von Wettbewerbsvorteilen werden, insbesondere wenn Startups Datennetzeffekte auslösen können (eine Situation, in der mehr Benutzer → mehr Daten → intelligentere Algorithmen → besseres Produkt → mehr Benutzer).
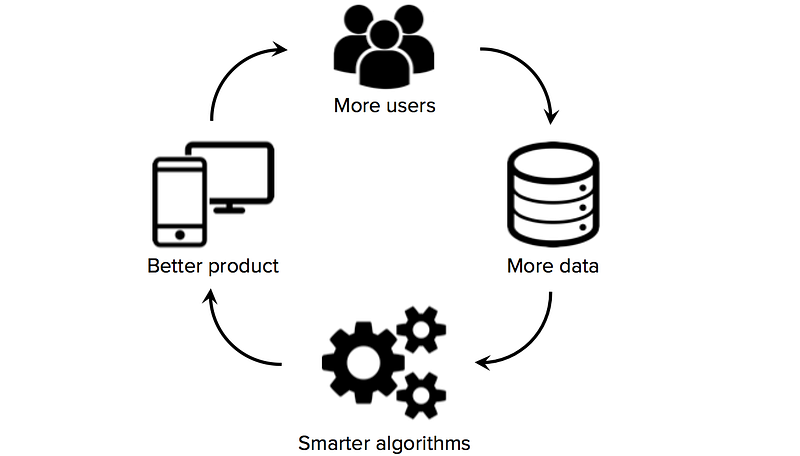
Folglich ist eine der wichtigsten strategischen Entscheidungen, die Startups für maschinelles Lernen treffen müssen, wie sie hochwertige Datensätze erstellen, um ihre Lernalgorithmen zu trainieren. Leider haben Startups am Anfang oft nur begrenzte oder gar keine markierten Daten, eine Situation, die Gründer daran hindert, signifikante Fortschritte beim Aufbau eines datengesteuerten Produkts zu erzielen. Es lohnt sich daher, die Strategien zur Datenerfassung von Anfang an zu erkunden, bevor Sie das Data Science-Team einstellen oder eine kostspielige Kerninfrastruktur aufbauen.
Startups können das Kaltstartproblem der Datenerfassung auf vielfältige Weise überwinden. Die Wahl der Datenstrategie / -quelle geht in der Regel Hand in Hand mit der Wahl des Geschäftsmodells, dem Fokus eines Startups (Consumer oder Enterprise, horizontal oder vertikal usw.).) und die Finanzierungssituation. Die folgende Liste von Strategien ist zwar weder erschöpfend noch schließt sie sich gegenseitig aus, vermittelt jedoch einen Eindruck von der breiten Palette der verfügbaren Ansätze.
Strategie #1: Manuelle Arbeit
Das Erstellen eines guten proprietären Datensatzes von Grund auf bedeutet fast immer, dass im Vorfeld viel menschlicher Aufwand in die Datenerfassung gesteckt und manuelle Aufgaben ausgeführt werden, die nicht skaliert werden können. Beispiele für Startups, die am Anfang rohe Gewalt angewendet haben, gibt es reichlich. Zum Beispiel beschäftigen viele Chatbot-Startups menschliche „KI-Trainer“, die die Vorhersagen ihrer virtuellen Agenten manuell erstellen oder überprüfen (mit unterschiedlichem Erfolg und hoher Fluktuationsrate). Selbst die Tech-Giganten greifen auf diese Strategie zurück: Alle Antworten von Facebook-Nutzern werden von einem Team von Auftragnehmern überprüft und bearbeitet.

Die Verwendung von Brute-Force zur manuellen Kennzeichnung von Datenpunkten kann eine erfolgreiche Strategie sein, solange die Auswirkungen des Datennetzwerks irgendwann eintreten, sodass Menschen nicht mehr mit der Kundenbasis skalieren können. Sobald sich das KI-System schnell genug verbessert, werden unspezifische Ausreißer seltener und die Anzahl der Menschen, die manuelle Beschriftungen durchführen, kann verringert oder konstant gehalten werden.
Interessant für: Mehr oder weniger jedes Machine Learning Startup
Beispiele:
- Viele Chatbot-Startups (einschließlich Magic, GoButler, x.ai und Clara)
- MetaMind (manuell gesammelter und beschrifteter Datensatz zur Lebensmittelklassifizierung)
- Building Radar (Mitarbeiter / Praktikanten beschriften manuell Bilder von Gebäuden)
Strategie #2: Verengen Sie die Domäne
Die meisten Startups werden versuchen, Daten direkt von Benutzern zu sammeln. Die Herausforderung besteht darin, Early Adopters davon zu überzeugen, das Produkt zu verwenden, bevor die Vorteile des maschinellen Lernens voll zum Tragen kommen (da Daten in erster Linie zum Trainieren und zur Feinabstimmung der Algorithmen benötigt werden). Eine Möglichkeit, diesen Catch-22 zu umgehen, besteht darin, die Problemdomäne drastisch einzuschränken (und den Umfang später bei Bedarf zu erweitern). Wie Chris Dixon sagt: „Die Menge an Daten, die Sie benötigen, hängt von der Breite des Problems ab, das Sie lösen möchten.“
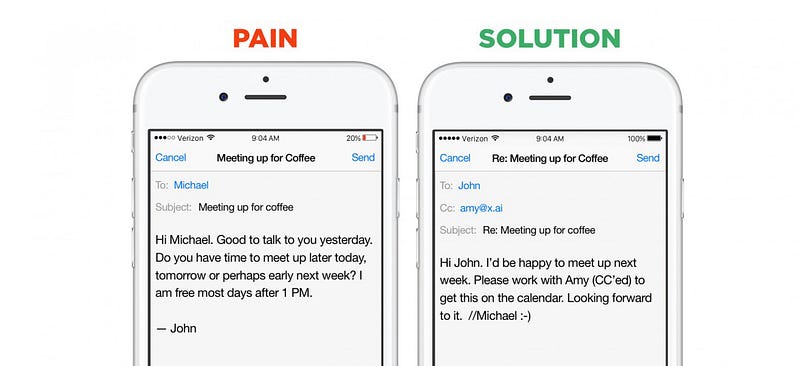
Gute Beispiele für die Vorteile einer engen Domäne sind wieder Chatbots. Startups in diesem Segment können zwischen zwei Go-to-Market—Strategien wählen: Sie können horizontale Assistenten bauen – Bots, die bei einer sehr großen Anzahl von Fragen und sofortigen Anfragen helfen können (Beispiele sind Viv, Magic, Awesome, Maluuba und Jam). Oder sie können vertikale Assistenten erstellen – Bots, die versuchen, einen bestimmten, genau definierten Job sehr gut auszuführen (Beispiele sind x.ai , Clara, DigitalGenius, Kasisto, Meekan — und mehr recentlyGoButler/Angel.ai). Während beide Ansätze gültig sind, ist die Datenerfassung für Startups, die Probleme mit geschlossenen Domänen angehen, erheblich einfacher.
Interessant für: Vertikal integrierte Unternehmen
Beispiele:
- Hochspezialisierte vertikale Chatbots (wie x.ai , Clara oder GoButler)
- Deep Genomics (verwendet Deep Learning zur Klassifizierung / Interpretation genetischer Varianten)
- Quantifizierte Haut (verwendet Kunden-Selfies zur Analyse der Haut einer Person)
Strategie #3: Crowdsourcing / Outsourcing
Anstatt qualifizierte Mitarbeiter (oder Praktikanten) zu verwenden, um Daten manuell zu sammeln oder zu kennzeichnen, können Startups den Prozess auch Crowdsourcing betreiben. Plattformen wie Amazon Mechanical Turk oder CrowdFlower bieten eine Möglichkeit, unordentliche und unvollständige Daten mit einer Online-Belegschaft von Millionen von Menschen zu bereinigen. Zum Beispiel nutzte VocalIQ (2015 von Apple übernommen) Amazons Mechanical Turk, um seinen digitalen Assistenten mit Tausenden von Benutzeranfragen zu versorgen. Arbeiter können auch ausgelagert werden, indem andere unabhängige Auftragnehmer beschäftigt werden (wie von getan) cyClara oder Facebook M). Die notwendige Bedingung für die Verwendung dieses Ansatzes ist, dass die Aufgabe klar erklärt werden kann und nicht zu lang / langweilig ist.

Eine weitere Taktik besteht darin, die Öffentlichkeit dazu anzuregen, freiwillig Daten beizutragen. Ein Beispiel ist Snips, ein in Paris ansässiges KI-Startup, das diesen Ansatz verwendet, um eine bestimmte Art von Daten (Bestätigungs-E-Mails für Restaurants, Hotels und Fluggesellschaften) in die Hände zu bekommen. Wie andere Startups verwendet Snips ein gamifiziertes System, bei dem Benutzer in einer Rangliste eingestuft werden.
Interessant für: Anwendungsfälle, in denen die Qualitätskontrolle leicht durchgesetzt werden kann
Beispiele:
- DeepMind, Maluuba, AlchemyAPI und viele andere (siehe hier)
- VocalIQ (verwendete Mechanical Turk, um seinem Programm beizubringen, wie Menschen sprechen)
- Snips (bittet die Leute, Daten für die Forschung frei beizutragen)
Strategie #4: User-in-the-Loop
Eine Crowdsourcing-Strategie, die eine eigene Kategorie verdient, ist User-in-the-Loop.Dieser Ansatz beinhaltet die Entwicklung von Produkten, die den Benutzern die richtigen Anreize bieten, Daten an das System zurückzugeben. Zwei klassische Beispiele für Unternehmen, die diesen Ansatz für viele ihrer Produkte verwendet haben, sind Google(automatische Vervollständigung in der Suche, Google Translate, Spam-Filter usw.) und Facebook (Benutzer, die Freunde in Fotos markieren). Den Nutzern ist oft nicht bewusst, dass sie diesen Unternehmen markierte Daten kostenlos zur Verfügung stellen.
Viele Startups im Bereich des maschinellen Lernens haben sich von Google und Facebook inspirieren lassen, indem sie Produkte mit einer fehlertoleranten UX entwickelt haben, die Benutzer ausdrücklich dazu ermutigen, Maschinenfehler zu korrigieren. Besonders bemerkenswert arere und Duolingo (beide von Luis von Ahn gegründet). Andere Beispiele umfassen Unbabel, Wit.ai und Mapillary.
Interessant für: Konsumentenzentrierte Startups mit konstanter Nutzerinteraktion
Beispiele:
- Unbabel (Community-Übersetzer korrigieren maschinell generierte Übersetzungen)
- Wit.ai (zur verfügung gestellt dashboard/API für benutzer zu korrigieren übersetzung fehler)
- Mapillary (benutzer können richtige maschine-erzeugt verkehrs zeichen erkennung)
Strategie #5: Nebengeschäft
Eine Strategie, die bei Computer Vision-Startups besonders beliebt zu sein scheint, besteht darin, eine kostenlose, domänenspezifische mobile App anzubieten, die sich an Verbraucher richtet. Clarifai, HyperVerge und Madbits (2014 von Twitter übernommen) verfolgen diese Strategie, indem sie Foto-Apps anbieten, die zusätzliche Bilddaten für ihr Kerngeschäft sammeln.
Diese Strategie ist nicht ganz ohne Risiko (schließlich kostet es Zeit und Geld, eine App erfolgreich zu entwickeln und zu bewerben). Startups müssen auch sicherstellen, dass sie einen ausreichend starken Anwendungsfall schaffen, der Benutzer dazu zwingt, ihre Daten aufzugeben, auch wenn dem Dienst zu Beginn die Vorteile von Datennetzwerkeffekten fehlen.
Interessant für: Enterprise Startups/horizontale Plattformen
Beispiele:
- Clarifai (Forevery, foto entdeckung app)
- HyperVerge (Silber, foto organisation app)
- Madbits (Momentsia, foto collage app)