av Moritz Mueller-Freitag, Elva strategi.
den” orimliga effektiviteten ” av data för maskininlärningsapplikationer har diskuterats i stor utsträckning genom åren (se här, här och här). Det har också föreslagits att många stora genombrott inom artificiell intelligens inte har begränsats av algoritmiska framsteg utan av tillgången till högkvalitativa datamängder (se här). Den röda tråden som går igenom dessa diskussioner är att data är en viktig komponent för att göra toppmodern maskininlärning.
tillgång till högkvalitativa utbildningsdata är avgörande för nystartade företag som använder maskininlärning som kärnteknologi i sin verksamhet. Medan många algoritmer och mjukvaruverktyg är öppna och delas över forskarsamhället, är bra datamängder vanligtvis proprietära och svåra att bygga. Att äga en stor, domänspecifika dataset kan därför bli en betydande källa till konkurrensfördelar, särskilt om startups kan jumpstart datanätverkseffekter (en situation där fler användare Bahrain mer data Bahrain smartare algoritmer Bahrain bättre produkt Bahrain fler användare).
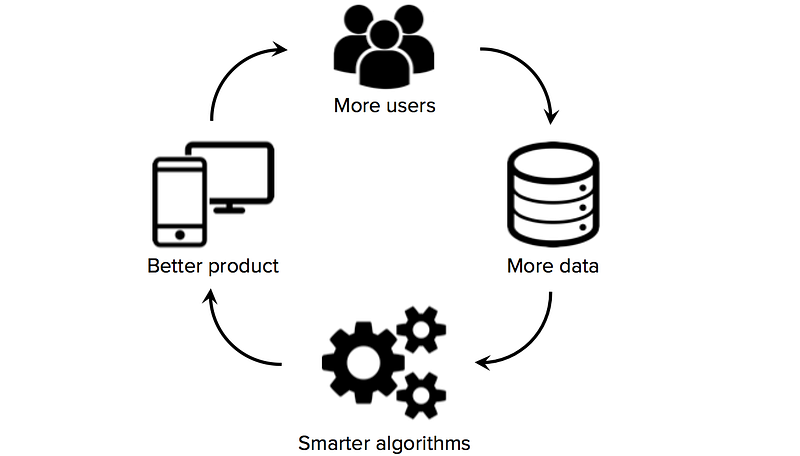
följaktligen är ett av de viktigaste strategiska besluten som maskininlärningsstart måste göra hur man bygger högkvalitativa dataset för att träna sina inlärningsalgoritmer. Tyvärr har startups ofta begränsad eller ingen märkt data i början, en situation som utesluter grundare från att göra betydande framsteg när det gäller att bygga en datadriven produkt. Det är därför värt att utforska datainsamlingsstrategier från början innan du anställer datavetenskapsteamet eller bygger upp en kostsam kärninfrastruktur.
Startups kan övervinna kallstartproblemet med datainsamling på många sätt. Valet av datastrategi / källa går vanligtvis hand i hand med valet av affärsmodell, en startfokus (konsument eller företag, horisontellt eller vertikalt, etc.) och finansieringssituationen. Följande lista med strategier, även om de varken är uttömmande eller utesluter varandra, ger en känsla för det breda utbudet av tillgängliga metoder.
strategi # 1: manuellt arbete
att bygga en bra proprietär dataset från början betyder nästan alltid att man lägger mycket på framsidan, mänsklig ansträngning i datainsamling och utför manuella uppgifter som inte skalar. Exempel på startups som har använt brute force i början är rikliga. Till exempel använder många chatbot-startups mänskliga ”AI-tränare” som manuellt skapar eller verifierar förutsägelserna som deras virtuella agenter gör (med varierande grad av framgång och hög personalomsättning). Även de tekniska jättarna tillgriper denna strategi: alla svar från Facebook M granskas och redigeras av ett team av entreprenörer.

att använda brute force för att manuellt märka datapunkter kan vara en framgångsrik strategi så länge datanätverkseffekter sparkar in någon gång så att människor inte längre skala i lika takt med kundbasen. Så snart AI-systemet förbättras tillräckligt snabbt blir ospecificerade avvikare mindre frekventa och antalet människor som utför manuell märkning kan minskas eller hållas konstant.
intressant för: mer eller mindre varje maskininlärning start
exempel:
- många chatbot startups (inklusive Magi, GoButler, x.ai och Clara)
- MetaMind (manuellt insamlad och märkt dataset för livsmedelsklassificering)
- Byggnadsradar (anställda/praktikanter märker manuellt bilder av byggnader)
strategi # 2: begränsa domänen
de flesta startups kommer att försöka samla in data direkt från användare. Utmaningen är att övertyga tidiga användare att använda produkten innan fördelarna med maskininlärning helt sparkar in (eftersom data behövs i första hand för att träna och finjustera algoritmerna). En väg runt denna catch – 22 är att drastiskt begränsa problemdomänen (och utöka omfattningen senare om det behövs). Som Chris Dixon säger: ”mängden data du behöver är i förhållande till bredden av problemet du försöker lösa.”
bra exempel på fördelarna med en smal domän är igen chatbots. Startups i det här segmentet kan välja mellan två go-to-market — strategier: de kan bygga horisontella assistenter-bots som kan hjälpa till med ett mycket stort antal frågor och omedelbara förfrågningar (exempel är Viv, Magic,Awesome, Maluuba och Jam). Eller de kan skapa vertikala assistenter-bots som försöker utföra ett specifikt, väldefinierat jobb extremt bra (exempel är x.ai, Clara, DigitalGenius, Kasisto — Meekan-och mer nyligobutler/Angel.ai). Medan båda metoderna är giltiga, datainsamling är dramatiskt lättare för nystartade företag som hanterar slutna domänproblem.
intressant för: vertikalt integrerade företag
exempel:
- högspecialiserade vertikala chatbots (som x.ai Clara eller GoButler)
- djup genomik (använder djupt lärande för att klassificera / tolka genetiska varianter)
- kvantifierad hud (använder kundselfies för att analysera en persons hud)
strategi # 3: Crowdsourcing / Outsourcing
istället för att använda kvalificerade medarbetare (eller praktikanter) för att manuellt samla in eller märka data, kan startups också crowdsource processen. Plattformar som Amazon Mechanical Turk eller CrowdFlower erbjuder ett sätt att städa upp röriga och ofullständiga data med hjälp av en online-arbetskraft på miljontals människor. Till exempel använde VocalIQ (förvärvad av Apple 2015) Amazons mekaniska Turk för att mata sin digitala assistent tusentals användarfrågor. Arbetstagare kan också läggas ut genom att anställa andra oberoende entreprenörer (som gjort byClara eller Facebook M). Det nödvändiga villkoret för att använda detta tillvägagångssätt är att uppgiften tydligt kan förklaras och inte är för lång/tråkig.

en annan taktik är att uppmuntra allmänheten att frivilligt bidra med data. Ett exempel är Snips, en Paris-baserad AI-start som använder detta tillvägagångssätt för att få tag på en viss typ av data (bekräftelsemail för restauranger, hotell och flygbolag). Liksom andra startups använder Snips ett gamifierat system där användare rankas på en leaderboard.
intressant för: Använd fall där kvalitetskontroll enkelt kan verkställas
exempel:
- DeepMind, Maluuba, AlchemyAPI och många andra (se här)
- VocalIQ (används Mekanisk Turk för att lära sitt program hur människor pratar)
- Snips (ber människor att fritt bidra med data för forskning)
strategi # 4: User-in-the-loop
en crowdsourcing-strategi som förtjänar sin egen kategori är user-in-the-loop.Detta tillvägagångssätt innebär att utforma produkter som ger rätt incitament för användare att ge data tillbaka till systemet. Två klassiska exempel på företag som har använt detta tillvägagångssätt för många av sina produkter är Google(autocomplete in search, Google Translate, spamfilter etc.) och Facebook(användare tagga vänner i bilder). Användare är ofta omedvetna om att de ger dessa företag med märkta data gratis.
många startups i maskininlärningsutrymmet har hämtat inspiration från Google och Facebook genom att skapa produkter med en feltolerant UX som uttryckligen uppmuntrar användare att korrigera maskinfel. Särskilt anmärkningsvärda arere och Duolingo (båda grundade av Luis von Ahn). Andra exempel är Unbabel, Wit.ai och Mapillary.
intressant för: konsumentcentrerade startups med konstant användarinteraktion
exempel:
- Unbabel (gemenskapsöversättare korrigerar maskingenererade översättningar)
- Wit.ai (tillhandahålls instrumentpanel / API för användare att korrigera översättningsfel)
- Mapillary (användare kan korrigera maskingenererad trafikskyltdetektering)
strategi # 5: Side business
en strategi som verkar vara särskilt populär bland startups för datorsyn är att erbjuda en gratis, domänspecifik mobilapp som riktar sig till konsumenter. Clarifai, HyperVerge och Madbits (förvärvade av Twitter 2014) har alla följt denna strategi genom att erbjuda fotoappar som samlar in ytterligare bilddata för sin kärnverksamhet.
denna strategi är inte helt utan risk (trots allt kostar det tid och pengar att framgångsrikt utveckla och marknadsföra en app). Startups måste också se till att de skapar ett tillräckligt starkt användningsfall som tvingar användarna att ge upp sina data, även om tjänsten saknar fördelarna med datanätverkseffekter i början.
intressant för: Enterprise startups / horisontella plattformar
exempel:
- Clarifai (Forevery, foto upptäckt app)
- HyperVerge (Silver, foto organisation app)
- Madbits( Momentsia, Foto collage app)