por Moritz Mueller-Freitag, Eleven Strategy.
a” eficácia irracional ” dos dados para aplicativos de aprendizado de máquina tem sido amplamente debatida ao longo dos anos (veja aqui, aqui e aqui). Também foi sugerido que muitos avanços importantes no campo da inteligência Artificial não foram limitados por avanços algorítmicos, mas pela disponibilidade de conjuntos de dados de alta qualidade (veja aqui). O tópico comum que percorre essas discussões é que os dados são um componente vital para fazer aprendizado de máquina de última geração.
Consequentemente, uma das principais decisões estratégicas de aprendizagem de máquina de startups tem que fazer é como criar de alta qualidade conjuntos de dados para treinar seus algoritmos de aprendizagem. Infelizmente, as startups geralmente têm dados limitados ou não rotulados no início, uma situação que impede os fundadores de fazer progressos significativos na construção de um produto orientado a dados. Portanto, vale a pena explorar as estratégias de aquisição de dados desde o início, antes de contratar a equipe de ciência de dados ou construir uma infraestrutura central cara.
as Startups podem superar o problema de arranque a frio da aquisição de dados de várias maneiras. A escolha da estratégia/fonte de dados geralmente anda de mãos dadas com a escolha do modelo de negócios, o foco de uma startup (consumidor ou empresa, horizontal ou vertical, etc.) e a situação do financiamento. A lista de estratégias a seguir, embora não seja exaustiva nem mutuamente exclusiva, dá sentido à ampla gama de abordagens disponíveis.
Estratégia #1: Trabalho Manual
construir um bom conjunto de dados proprietário do zero quase sempre significa colocar muito esforço humano na aquisição de dados e executar tarefas manuais que não escalam. Exemplos de startups que usaram Força bruta no início são abundantes. Por exemplo, muitas startups de chatbot empregam “Treinadores de IA” humanos que criam ou verificam manualmente as previsões que seus agentes virtuais fazem (com vários graus de sucesso e uma alta taxa de rotatividade de funcionários). Até os gigantes da tecnologia recorrem a essa estratégia: todas as respostas do Facebook M são revisadas e editadas por uma equipe de contratados.

Usando a força bruta para etiquetar manualmente os pontos de dados pode ser uma estratégia bem sucedida desde que dados os efeitos de rede chutar, em algum ponto para que os seres humanos deixam de escala no mesmo ritmo com a base de clientes. Assim que o sistema de IA está melhorando rápido o suficiente, os outliers não especificados tornam-se menos frequentes e o número de humanos que realizam a rotulagem manual pode ser diminuído ou mantido constante.
interessante para: mais ou menos cada inicialização de aprendizado de máquina
exemplos:
- Muitos chatbot startups (incluindo Magia, GoButler, x.ai e Clara)
- MetaMind (manualmente coletados e rotulados de conjunto de dados para alimentação de classificação)
- Construção de Radar (funcionários/estagiários manualmente rótulo de fotos de edifícios)
Estratégia #2: restringir o domínio
a Maioria das startups vai tentar recolher dados diretamente dos usuários. O desafio é convencer os primeiros a usar o produto antes que os benefícios do aprendizado de máquina entrem totalmente (porque os dados são necessários em primeiro lugar para treinar e ajustar os algoritmos). Uma maneira de contornar esse catch-22 é restringir drasticamente o domínio do problema (e expandir o escopo mais tarde, se necessário). Como Chris Dixon diz: “a quantidade de dados que você precisa é relativa à amplitude do problema que você está tentando resolver.”
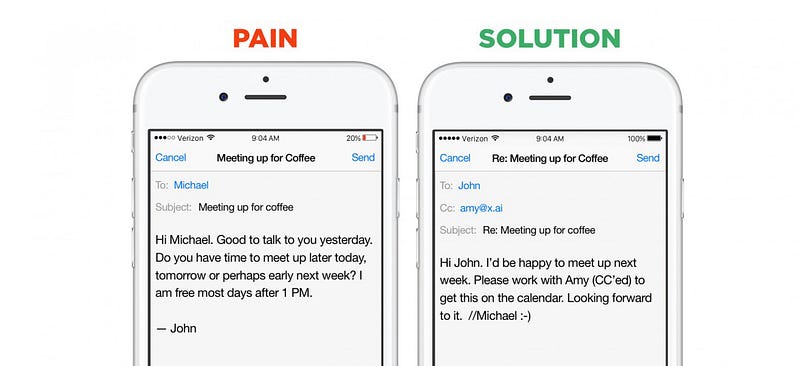
bons exemplos dos benefícios de um domínio estreito são novamente chatbots. Startups neste segmento podem escolher entre duas estratégias de go-to-market: eles podem construir assistentes horizontais-bots que podem ajudar com um número muito grande de perguntas e solicitações imediatas (exemplos são Viv, Magic,Awesome, Maluuba e Jam). Ou eles podem criar assistentes verticais-bots que tentam executar um trabalho específico e bem definido extremamente bem (exemplos são x.ai, Clara, DigitalGenius, Kasisto, Meekan – e mais recentementegobutler / Angel. ai). Embora ambas as abordagens sejam válidas, a coleta de dados é dramaticamente mais fácil para startups que enfrentam problemas de domínio fechado.
Interessante para: Verticalmente integrada de negócios
Exemplos:
- Altamente especializados vertical chatterbots (como x.ai, Clara ou GoButler)
- Profundo Genômica (usa profunda aprender a classificar/interpretar variantes genéticas)
- Quantificados Pele (usa o cliente selfies para analisar a pele de uma pessoa)
Estratégia #3: Crowdsourcing / Outsourcing
em vez de usar funcionários qualificados (ou estagiários) para coletar ou rotular dados manualmente, as startups também podem crowdsource o processo. Plataformas como Amazon Mechanical Turk ou CrowdFlower oferecem uma maneira de Limpar dados confusos e incompletos usando uma força de trabalho on-line de milhões de pessoas. Por exemplo, a VocalIQ (adquirida pela Apple em 2015) usou o Mechanical Turk da Amazon para alimentar seu assistente digital com milhares de consultas de usuários. Os trabalhadores também podem ser terceirizados empregando outros contratados independentes (como feito byClara ou Facebook M). A condição necessária para usar essa abordagem é que a tarefa possa ser claramente explicada e não seja muito longa/chata.

Outra tática é incentivar o público a contribuir voluntariamente dados. Um exemplo é o Snips, uma startup de IA com sede em Paris que usa essa abordagem para colocar as mãos em um determinado tipo de dados (e-mails de confirmação para restaurantes, hotéis e companhias aéreas). Como outras startups, Snips usa um sistema gamificado onde os usuários são classificados em uma tabela de classificação.
interessante para: Casos de uso onde o controle de qualidade pode ser facilmente aplicada
Exemplos:
- DeepMind, Maluuba, AlchemyAPI e muitos outros (ver aqui)
- VocalIQ (usado Mechanical Turk para ensinar o seu programa, como as pessoas falam)
- Snips (pede às pessoas para se livremente contribuir com dados para a pesquisa)
Estratégia #4: Usuário-in-the-loop
Uma estratégia de crowdsourcing que merece a sua própria categoria de usuário-in-the-loop.Essa abordagem envolve o design de produtos que fornecem os incentivos certos para os usuários devolverem dados ao sistema. Dois exemplos clássicos de empresas que usaram essa abordagem para muitos de seus produtos são o Google(preenchimento automático na Pesquisa, Google Translate, filtros de spam, etc.) e Facebook (Usuários marcando amigos em fotos). Os usuários geralmente não sabem que fornecem a essas empresas dados rotulados gratuitamente.
muitas startups no espaço de aprendizado de máquina se inspiraram no Google e no Facebook criando produtos com UX tolerante a falhas que incentivam explicitamente os usuários a corrigir erros de máquina. Particularmente notável arere e Duolingo (ambos fundados por Luis von Ahn). Outros exemplos incluem Unbabel, Wit.ai e Mapilar.
Interessante para: centrada no Consumidor startups com constante interação com o usuário
Exemplos:
- Unbabel (comunidade de tradutores máquina correta-traduções geradas)
- Sagacidade.ai (desde dashboard/API para usuários, para corrigir erros de tradução)
- Mapillary (os usuários podem corrigir máquina de tráfego gerado pelo sinal de detecção de)
Estratégia #5: Side business
uma estratégia que parece ser particularmente popular entre as startups de visão computacional é oferecer um aplicativo móvel gratuito e específico de domínio que visa os consumidores. Clarifai, HyperVerge e Madbits (adquiridos pelo Twitter em 2014) adotaram essa estratégia oferecendo aplicativos de fotos que coletam dados de imagem adicionais para seus negócios principais.
esta estratégia não é completamente sem risco (afinal, custa tempo e dinheiro para desenvolver e promover com sucesso um aplicativo). As Startups também devem garantir que criem um caso de uso forte o suficiente que obrigue os usuários a desistir de seus dados, mesmo que o serviço não tenha os benefícios dos efeitos da rede de dados no início.
interessante para: startups empresariais / plataformas horizontais
exemplos:
- Clarifai (Forevery, foto descoberta app)
- HyperVerge (Prata, organização de fotos app)
- Madbits (Momentsia, colagem de fotos do app)