Moritz Mueller-Freitag, Eleven Strategy.
„nieuzasadniona skuteczność” danych w aplikacjach uczenia maszynowego była przez lata szeroko dyskutowana (patrz tutaj, tutaj i tutaj). Zasugerowano również, że wiele znaczących przełomów w dziedzinie sztucznej inteligencji nie zostało ograniczonych przez postęp algorytmiczny, ale przez dostępność wysokiej jakości zbiorów danych (patrz tutaj). Wspólnym wątkiem tych dyskusji jest to, że dane są istotnym elementem w procesie najnowocześniejszego uczenia maszynowego.
dostęp do wysokiej jakości danych szkoleniowych ma kluczowe znaczenie dla startupów, które wykorzystują uczenie maszynowe jako podstawową technologię swojej działalności. Podczas gdy wiele algorytmów i narzędzi programowych jest open source i udostępnianych przez społeczność badawczą, dobre zbiory danych są zwykle zastrzeżone i trudne do zbudowania. Posiadanie dużego, specyficznego dla domeny zbioru danych może zatem stać się znaczącym źródłem przewagi konkurencyjnej, zwłaszcza jeśli startupy mogą przyspieszyć efekty sieci danych (sytuacja, w której więcej użytkowników → więcej danych → inteligentniejsze algorytmy → lepszy produkt → więcej użytkowników).
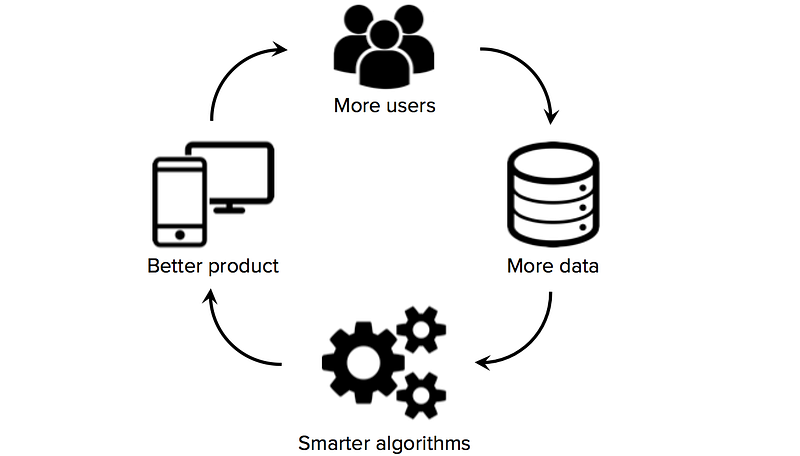
w związku z tym jedną z kluczowych decyzji strategicznych, które muszą podjąć startupy uczące się maszynowo, jest tworzenie wysokiej jakości zestawów danych do szkolenia ich algorytmów uczenia się. Niestety, startupy często mają na początku ograniczone lub nie mają oznaczonych danych, co uniemożliwia założycielom poczynienie znaczących postępów w budowaniu produktu opartego na danych. Warto więc od samego początku badać strategie pozyskiwania danych, zanim zatrudnimy zespół analityków danych lub zbudujemy kosztowną podstawową infrastrukturę.
startupy mogą przezwyciężyć problem pozyskiwania danych na zimno na wiele sposobów. Wybór strategii/źródła danych zwykle idzie w parze z wyborem modelu biznesowego, ukierunkowaniem startupu (konsument lub przedsiębiorstwo, poziome lub pionowe itp.) oraz sytuacji finansowej. Poniższa lista strategii, choć nie jest ani wyczerpująca, ani wzajemnie się wykluczająca, daje sens szerokiemu zakresowi dostępnych podejść.
Strategia #1: Praca ręczna
budowanie dobrego, zastrzeżonego zbioru danych od podstaw prawie zawsze oznacza wkładanie wielu wysiłków z góry, ludzkich w gromadzenie danych i wykonywanie zadań ręcznych, które nie skalują się. Przykłady startupów, które na początku używały brute force, są obfite. Na przykład wiele startupów chatbotów zatrudnia ludzkich „trenerów AI”, którzy ręcznie tworzą lub weryfikują prognozy ich wirtualnych agentów (z różnym stopniem sukcesu i wysokim wskaźnikiem rotacji pracowników). Nawet giganci technologiczni uciekają się do tej strategii: wszystkie odpowiedzi Facebooka M są przeglądane i edytowane przez zespół wykonawców.

używanie brutalnej siły do ręcznego etykietowania punktów danych może być skuteczną strategią, o ile w pewnym momencie pojawią się efekty sieci danych, dzięki czemu ludzie nie będą już skalować się w równym tempie z bazą klientów. Jak tylko system AI poprawia się wystarczająco szybko, nieokreślone wartości odstające stają się rzadsze, a liczba ludzi, którzy wykonują ręczne etykietowanie, może zostać zmniejszona lub utrzymana na stałym poziomie.
interesujące dla: mniej więcej każdego startupu uczenia maszynowego
przykłady:
- wiele startupów chatbotów (m.in. Magic, GoButler, x.ai i Clara)
- MetaMind (ręcznie zbierany i oznaczany zestaw danych do klasyfikacji żywności)
- Radar budowlany (pracownicy / stażyści ręcznie etykietują zdjęcia budynków)
Strategia # 2: Zawęź domenę
większość startupów będzie próbowała zbierać dane bezpośrednio od użytkowników. Wyzwaniem jest przekonanie wczesnych użytkowników do korzystania z produktu, zanim w pełni wykorzystają korzyści płynące z uczenia maszynowego (ponieważ dane są potrzebne przede wszystkim do szkolenia i dostrojenia algorytmów). Jednym ze sposobów obejścia tego catch-22 jest drastyczne zawężenie domeny problemowej (i rozszerzenie zakresu później, jeśli zajdzie taka potrzeba). Jak mówi Chris Dixon: „ilość potrzebnych danych zależy od zakresu problemu, który próbujesz rozwiązać.”
dobrymi przykładami korzyści płynących z wąskiej domeny są ponownie chatboty. Startupy w tym segmencie mogą wybierać między dwiema strategiami wejścia na rynek: mogą budować poziomych asystentów-botów, które mogą pomóc w bardzo dużej liczbie pytań i natychmiastowych próśb (przykłady to Viv, Magic,Awesome, Maluuba i Jam). Albo mogą tworzyć pionowe asystentki — boty, które starają się wykonać jedną konkretną, dobrze zdefiniowaną pracę (przykładami są x.ai, Clara, DigitalGenius, Kasisto — Meekan – a ostatnio także Angel. ai). Chociaż oba podejścia są prawidłowe, zbieranie danych jest znacznie łatwiejsze dla startupów, które rozwiązują problemy z domeną zamkniętą.
interesujące dla: firmy zintegrowane pionowo
przykłady:
- wysoko wyspecjalizowane pionowe chatboty (takie jak x.ai, Clara lub GoButler)
- Deep Genomics (wykorzystuje głębokie uczenie do klasyfikacji / interpretacji wariantów genetycznych)
- Skin Quantified (wykorzystuje Selfie klienta do analizy skóry osoby)
Strategia # 3: Crowdsourcing / Outsourcing
zamiast używać wykwalifikowanych pracowników (lub stażystów) do ręcznego zbierania lub etykietowania danych, startupy mogą również crowdsourcing procesu. Platformy takie jak Amazon Mechanical Turk lub CrowdFlower oferują sposób na oczyszczenie niechlujnych i niekompletnych danych przy użyciu siły roboczej milionów ludzi online. Na przykład VocalIQ (przejęty przez Apple w 2015 r.) wykorzystał mechanicznego Turka Amazona, aby nakarmić jego cyfrowego asystenta tysiącami zapytań użytkowników. Pracownicy mogą być również zleceniodawcy poprzez zatrudnianie innych niezależnych wykonawców (jak to robione przez firmę cclara lub Facebook m). Warunkiem koniecznym do zastosowania takiego podejścia jest to, że zadanie może być jasno wyjaśnione i nie jest zbyt długie/nudne.

kolejną taktyką jest zachęcenie społeczeństwa do dobrowolnego przekazywania danych. Przykładem jest snips, Paryski startup AI, który wykorzystuje to podejście do uzyskania określonego rodzaju danych (wiadomości e-mail z potwierdzeniem dla restauracji, hoteli i linii lotniczych). Podobnie jak inne startupy, Snips używa gamifikowanego systemu, w którym użytkownicy są klasyfikowani na tablicy wyników.
ciekawe dla: Przypadki użycia, w których kontrola jakości może być łatwo egzekwowana
przykłady:
- DeepMind, Maluuba, AlchemyAPI i wiele innych (czytaj tutaj)
- VocalIQ (użył mechanicznego Turka do nauczenia swojego programu, jak ludzie mówią)
- Snips (prosi ludzi o swobodne przesyłanie danych do badań)
Strategia # 4: User-in-the-loop
strategia crowdsourcingowa, która zasługuje na własną kategorię, to user-in-the-loop.Podejście to polega na projektowaniu produktów, które zapewniają użytkownikom właściwe zachęty do oddawania danych do systemu. Dwa klasyczne przykłady firm, które zastosowały to podejście do wielu swoich produktów to Google (autocomplete in search, Google Translate, filtry antyspamowe itp.) i Facebook (użytkownicy tagujący znajomych na zdjęciach). Użytkownicy często nie są świadomi, że dostarczają tym firmom oznaczone dane za darmo.
wiele startupów w przestrzeni uczenia maszynowego czerpało inspirację z Google i Facebooka, tworząc produkty z odpornym na błędy interfejsem użytkownika, które wyraźnie zachęcają użytkowników do poprawiania błędów maszynowych. Szczególnie godne uwagi są arere i Duolingo (oba założone przez Luisa von Ahna). Inne przykłady to Unbabel, Wit.ai i Mapillary.
interesujące dla: startupów zorientowanych na klienta ze stałą interakcją z użytkownikiem
przykłady:
- Unbabel (Tłumacze społeczności poprawiają tłumaczenia generowane maszynowo)
- Wit.ai (dostarczony pulpit nawigacyjny/API dla użytkowników w celu skorygowania błędów tłumaczenia)
- Mapillary (użytkownicy mogą poprawić wykrywanie znaków drogowych generowanych przez maszynę)
Strategia # 5: Side business
strategia, która wydaje się być szczególnie popularna wśród startupów z branży komputerowej, polega na oferowaniu bezpłatnej, specyficznej dla domeny aplikacji mobilnej skierowanej do konsumentów. Clarifai, HyperVerge i Madbits (przejęte przez Twitter w 2014) realizowały tę strategię, oferując aplikacje do zdjęć, które zbierają dodatkowe dane obrazowe dla swojej podstawowej działalności.
ta strategia nie jest całkowicie pozbawiona ryzyka (w końcu pomyślne opracowanie i promowanie aplikacji kosztuje czas i pieniądze). Startupy muszą również zapewnić, że stworzą wystarczająco silny przypadek użycia, który zmusi użytkowników do rezygnacji z danych, nawet jeśli usługa nie ma korzyści z efektów sieci danych na początku.
interesujące dla: startupów przedsiębiorstw / platform poziomych
przykłady:
- Clarifai (Forevery, Photo discovery app)
- HyperVerge (Silver, Photo organization app)
- Madbits (Momentsia, Photo collage app)