Por Moritz Mueller-Freitag, Eleven Strategy.
La «eficacia irrazonable» de los datos para aplicaciones de aprendizaje automático ha sido ampliamente debatida a lo largo de los años (ver aquí, aquí y aquí). También se ha sugerido que muchos avances importantes en el campo de la Inteligencia Artificial no se han visto limitados por avances algorítmicos, sino por la disponibilidad de conjuntos de datos de alta calidad (ver aquí). El hilo conductor de estas discusiones es que los datos son un componente vital en el aprendizaje automático de última generación.
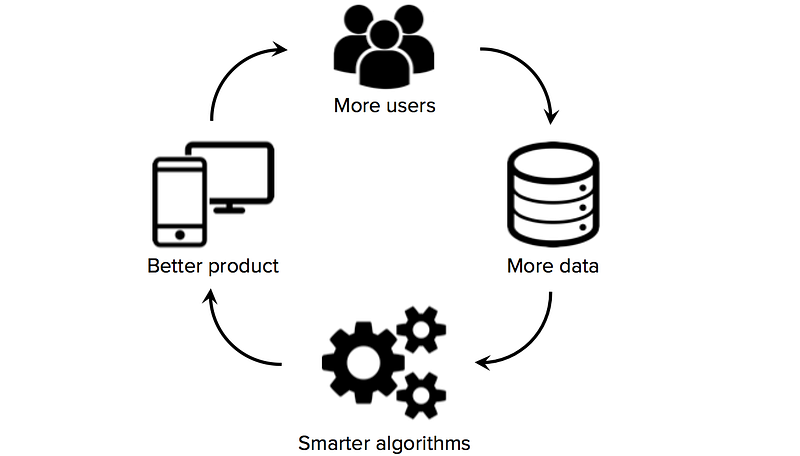
El acceso a datos de formación de alta calidad es fundamental para las empresas emergentes que utilizan el aprendizaje automático como la tecnología principal de su negocio. Si bien muchos algoritmos y herramientas de software son de código abierto y se comparten en toda la comunidad de investigación, los buenos conjuntos de datos generalmente son propietarios y difíciles de construir. Por lo tanto, poseer un conjunto de datos grande y específico de dominio puede convertirse en una fuente significativa de ventaja competitiva, especialmente si las startups pueden impulsar los efectos de red de datos (una situación en la que más usuarios → más datos → algoritmos más inteligentes → mejor producto → más usuarios).
En consecuencia, una de las decisiones estratégicas clave que deben tomar las startups de aprendizaje automático es cómo crear conjuntos de datos de alta calidad para entrenar sus algoritmos de aprendizaje. Desafortunadamente, las startups a menudo tienen datos limitados o no etiquetados al principio, una situación que impide a los fundadores hacer un progreso significativo en la construcción de un producto basado en datos. Por lo tanto, vale la pena explorar estrategias de adquisición de datos desde el principio, antes de contratar al equipo de ciencia de datos o construir una costosa infraestructura central.
Las startups pueden superar el problema del arranque en frío de la adquisición de datos de numerosas maneras. La elección de la estrategia/fuente de datos suele ir de la mano con la elección del modelo de negocio, el enfoque de una startup (consumidor o empresa, horizontal o vertical, etc.).) y la situación financiera. La lista de estrategias que figura a continuación, aunque no es exhaustiva ni se excluye mutuamente, da una idea de la amplia gama de enfoques disponibles.
Estrategia # 1: Trabajo manual
Construir un buen conjunto de datos propietario desde cero casi siempre significa poner mucho esfuerzo humano por adelantado en la adquisición de datos y realizar tareas manuales que no se escalan. Abundan los ejemplos de startups que han utilizado la fuerza bruta al principio. Por ejemplo, muchas startups de chatbots emplean «entrenadores de IA» humanos que crean o verifican manualmente las predicciones que hacen sus agentes virtuales (con diferentes grados de éxito y una alta tasa de rotación de empleados). Incluso los gigantes tecnológicos recurren a esta estrategia: todas las respuestas de Facebook M son revisadas y editadas por un equipo de contratistas.

Usar fuerza bruta para etiquetar manualmente los puntos de datos puede ser una estrategia exitosa siempre y cuando los efectos de red de datos se activen en algún momento para que los humanos ya no escalen al mismo ritmo que la base de clientes. Tan pronto como el sistema de IA mejora lo suficientemente rápido, los valores atípicos no especificados se vuelven menos frecuentes y el número de seres humanos que realizan el etiquetado manual puede reducirse o mantenerse constante.
Interesante para: Más o menos cada inicio de aprendizaje automático
Ejemplos:
- Muchas startups de chatbot (incluyendo Magic, GoButler, x.ai y Clara)
- MetaMind (conjunto de datos recopilados y etiquetados manualmente para la clasificación de alimentos)
- Radar de edificios (empleados / internos etiquetan manualmente imágenes de edificios)
Estrategia # 2: Reducir el dominio
La mayoría de las startups intentarán recopilar datos directamente de los usuarios. El reto consiste en convencer a los primeros usuarios de usar el producto antes de que los beneficios del aprendizaje automático se hagan efectivos por completo (porque los datos son necesarios en primer lugar para entrenar y ajustar los algoritmos). Una forma de evitar este catch – 22 es reducir drásticamente el dominio del problema (y ampliar el alcance más adelante si es necesario). Como dice Chris Dixon: «La cantidad de datos que necesita es relativa a la amplitud del problema que está tratando de resolver.»
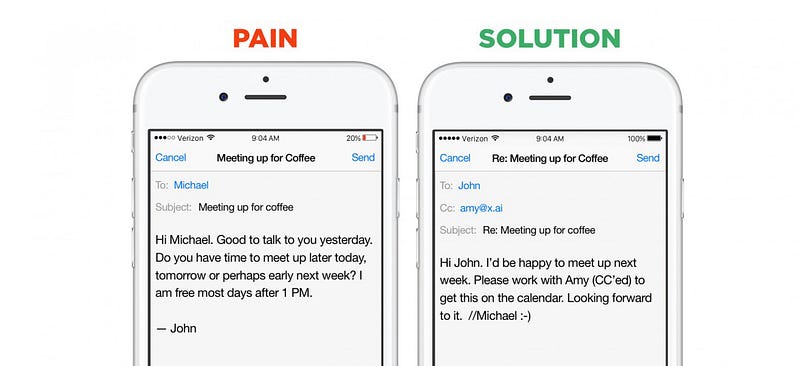
Los buenos ejemplos de los beneficios de un dominio estrecho son de nuevo los chatbots. Las startups de este segmento pueden elegir entre dos estrategias de lanzamiento al mercado: Pueden construir asistentes horizontales-bots que pueden ayudar con un gran número de preguntas y solicitudes inmediatas (ejemplos son Viv, Magic,Awesome, Maluuba y Jam). O pueden crear asistentes verticales: bots que intentan realizar un trabajo específico y bien definido de manera extremadamente buena (los ejemplos son x.ai, Clara, DigitalGenius, Kasisto, Meekan – y más recientemente Gobutler / Angel. ai). Si bien ambos enfoques son válidos, la recopilación de datos es mucho más fácil para las startups que abordan problemas de dominio cerrado.
Interesante para: Empresas integradas verticalmente
Ejemplos:
- Chatbots verticales altamente especializados (como x.ai, Clara o GoButler)
- Genómica profunda (utiliza el aprendizaje profundo para clasificar/interpretar variantes genéticas)
- Piel cuantificada (utiliza selfies de clientes para analizar la piel de una persona)
Estrategia Nº 3: Crowdsourcing / Outsourcing
En lugar de usar empleados calificados (o pasantes) para recopilar o etiquetar datos manualmente, las startups también pueden hacer crowdsourcing en el proceso. Plataformas como Amazon Mechanical Turk o CrowdFlower ofrecen una forma de limpiar datos desordenados e incompletos utilizando una fuerza de trabajo en línea de millones de personas. Por ejemplo, VocalIQ (adquirido por Apple en 2015) utilizó Mechanical Turk de Amazon para alimentar a su asistente digital con miles de consultas de usuarios. Los trabajadores también pueden ser subcontratados mediante el empleo de otros contratistas independientes (como se hace por Clara o Facebook M). La condición necesaria para utilizar este enfoque es que la tarea se pueda explicar claramente y no sea demasiado larga/aburrida.

Otra táctica es la de incentivar al público a contribuir voluntariamente datos. Un ejemplo es Snips, una startup de IA con sede en París que utiliza este enfoque para obtener cierto tipo de datos (correos electrónicos de confirmación para restaurantes, hoteles y aerolíneas). Al igual que otras startups, Snips utiliza un sistema gamificado donde los usuarios se clasifican en una tabla de clasificación.
Interesante para: Casos de uso en los que el control de calidad se puede aplicar fácilmente
Ejemplos:
- DeepMind, Maluuba, AlchemyAPI y muchos otros (ver aquí)
- VocalIQ (usó a Mechanical Turk para enseñar a su programa cómo habla la gente)
- Snips (pide a la gente que aporte datos libremente para la investigación)
Estrategia # 4: Usuario en bucle
Una estrategia de crowdsourcing que merece su propia categoría es usuario en bucle.Este enfoque implica diseñar productos que proporcionen los incentivos adecuados para que los usuarios devuelvan los datos al sistema. Dos ejemplos clásicos de empresas que han utilizado este enfoque para muchos de sus productos son Google(autocompletar en búsqueda, Google Translate, filtros de spam, etc.) y Facebook (usuarios etiquetando amigos en fotos). Los usuarios a menudo no saben que proporcionan a estas empresas datos etiquetados de forma gratuita.
Muchas empresas emergentes en el espacio del aprendizaje automático se han inspirado en Google y Facebook creando productos con una experiencia de usuario tolerante a fallos que alientan explícitamente a los usuarios a corregir errores de máquina. Particularmente notables son arere y Duolingo (ambos fundados por Luis von Ahn). Otros ejemplos incluyen Unbabel, el Ingenio.ai y Mapillary.
Interesante para: startups centradas en el consumidor con interacción constante con el usuario
Ejemplos:
- Sin etiqueta (traductores comunitarios corrigen traducciones generadas por máquina)
- Wit.ai (panel de control/API proporcionado para que los usuarios corrijan errores de traducción)
- Mapillary (los usuarios pueden corregir la detección de señales de tráfico generada por máquinas)
Estrategia # 5: Negocio paralelo
Una estrategia que parece ser particularmente popular entre las startups de visión artificial es ofrecer una aplicación móvil gratuita específica para el dominio que se dirige a los consumidores. Clarifai, HyperVerge y Madbits (adquiridos por Twitter en 2014) han seguido esta estrategia ofreciendo aplicaciones fotográficas que recopilan datos de imágenes adicionales para su negocio principal.
Esta estrategia no está completamente exenta de riesgos (después de todo, desarrollar y promocionar una aplicación con éxito cuesta tiempo y dinero). Las startups también deben asegurarse de crear un caso de uso lo suficientemente sólido que obligue a los usuarios a renunciar a sus datos, incluso si el servicio carece de los beneficios de los efectos de red de datos al principio.
Interesante para: Startups empresariales/plataformas horizontales
Ejemplos:
- Clarifai (Forevery, aplicación de descubrimiento de fotos)
- HyperVerge (Silver, aplicación de organización de fotos)
- Madbits (Momentsia, aplicación de collage de fotos)