af Mueller-Freitag, elleve strategi.
den “urimelige effektivitet” af data til maskinlæringsapplikationer er blevet bredt debatteret gennem årene (se her, her og her). Det er også blevet foreslået, at mange store gennembrud inden for kunstig intelligens ikke er blevet begrænset af algoritmiske fremskridt, men af tilgængeligheden af datasæt af høj kvalitet (se her). Den røde tråd, der løber gennem disse diskussioner, er, at data er en vigtig komponent i at gøre state-of-the-art maskinindlæring.
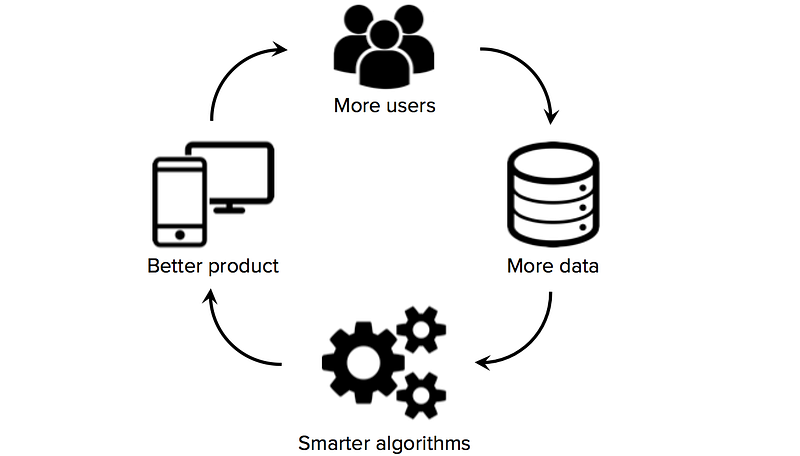
adgang til træningsdata af høj kvalitet er afgørende for startups, der bruger maskinlæring som kerneteknologi i deres forretning. Mens mange algoritmer og programmelværktøjer er åbne og deles på tværs af forskningsmiljøet, er gode datasæt normalt proprietære og svære at bygge. At eje et stort, domænespecifikt datasæt kan derfor blive en betydelig kilde til konkurrencefordel, især hvis startups kan kickstarte datanetværkseffekter (en situation, hvor flere brugere får flere data, får smartere algoritmer bedre produkt får flere brugere).
derfor er en af de vigtigste strategiske beslutninger, som opstart af maskinlæring skal tage, hvordan man bygger datasæt af høj kvalitet til at træne deres læringsalgoritmer. Desværre har startups ofte begrænsede eller ingen mærkede data i starten, en situation, der forhindrer grundlæggerne i at gøre betydelige fremskridt med at opbygge et datadrevet produkt. Det er derfor værd at undersøge dataindsamlingsstrategier fra starten, inden du ansætter data science-teamet eller opbygger en dyr kerneinfrastruktur.
Startups kan overvinde koldstartproblemet med dataindsamling på mange måder. Valget af datastrategi/kilde går normalt hånd i hånd med valget af forretningsmodel, en opstarts fokus (forbruger eller virksomhed, vandret eller lodret osv.) og finansieringssituationen . Følgende liste over strategier, mens hverken udtømmende eller gensidigt udelukkende, giver en mening for den brede vifte af tilgange til rådighed.
strategi #1: manuelt arbejde
opbygning af et godt proprietært datasæt fra bunden betyder næsten altid at lægge en masse up-front, menneskelig indsats i dataindsamling og udføre manuelle opgaver, der ikke skalerer. Eksempler på startups, der har brugt brute force i starten, er rigelige. For eksempel anvender mange chatbot-startups menneskelige “AI-undervisere”, der manuelt opretter eller verificerer de forudsigelser, deres virtuelle agenter foretager (med varierende grad af succes og en høj medarbejderomsætningshastighed). Selv tech giants ty til denne strategi: alle svar fra Facebook M gennemgås og redigeres af et team af entreprenører.

brug af brute force til manuelt at mærke datapunkter kan være en vellykket strategi, så længe datanetværkseffekter sparker ind på et tidspunkt, så mennesker ikke længere skalerer i samme tempo som kundebasen. Så snart AI-systemet forbedres hurtigt nok, bliver uspecificerede outliers mindre hyppige, og antallet af mennesker, der udfører manuel mærkning, kan reduceres eller holdes konstant.
interessant for: mere eller mindre hver maskinlæring opstart
eksempler:
- mange chatbot startups (herunder magi, GoButler ,x.ai og Clara)
- MetaMind (manuelt indsamlet og mærket datasæt til fødevareklassificering)
- Bygningsradar (medarbejdere/praktikanter mærker manuelt billeder af bygninger)
strategi #2: Begræns domænet
de fleste startups vil forsøge at indsamle data direkte fra brugerne. Udfordringen er at overbevise tidlige adoptører om at bruge produktet, før fordelene ved maskinindlæring fuldt ud sparker ind (fordi data er nødvendige i første omgang for at træne og finjustere algoritmerne). En måde omkring denne catch – 22 er at drastisk indsnævre problemdomænet (og udvide omfanget senere, hvis det er nødvendigt). “Mængden af data, du har brug for, er i forhold til bredden af det problem, du forsøger at løse.”
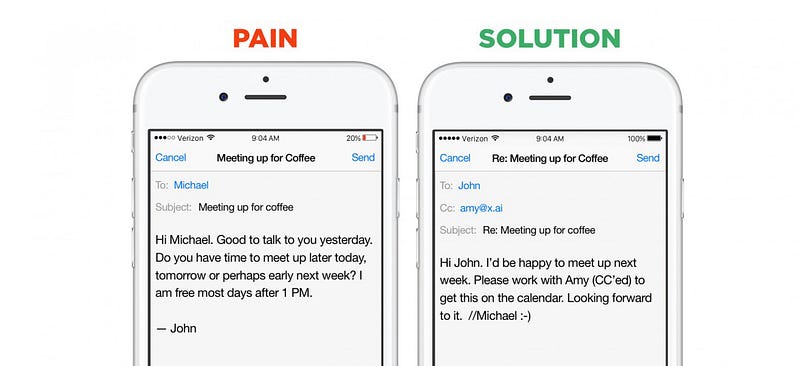
gode eksempler på fordelene ved et smalt domæne er igen chatbots. Startups i dette segment kan vælge mellem to go-to-market — strategier: de kan bygge vandrette assistenter-bots, der kan hjælpe med et meget stort antal spørgsmål og øjeblikkelige anmodninger (eksempler er viv,Magic, fantastisk, Maluuba og Jam). Eller de kan oprette lodrette assistenter-bots, der forsøger at udføre et specifikt, veldefineret job ekstremt godt (eksempler er x.ai, Clara, DigitalGenius, Kasisto, Meekan — og mere for nyliggobutler/Angel.ai). Mens begge tilgange er gyldige, dataindsamling er dramatisk lettere for startups, der tackler problemer med lukket domæne.
interessant for: vertikalt integrerede virksomheder
eksempler:
- højt specialiserede lodrette chatbots (såsom x.ai, Clara eller GoButler)
- Dyb genomik (bruger dyb læring til at klassificere/fortolke genetiske varianter)
- kvantificeret hud (bruger kundens selfies til at analysere en persons hud)
strategi # 3: Outsourcing
i stedet for at bruge kvalificerede medarbejdere (eller praktikanter) til manuelt at indsamle eller mærke data, kan startups også samle processen. Platforme som

en anden taktik er at tilskynde offentligheden til frivilligt at bidrage med data. Et eksempel er Snips, en Paris-baseret AI-opstart, der bruger denne tilgang til at få hænderne på en bestemt type data (bekræftelses-e-mails til restauranter, hoteller og flyselskaber). Ligesom andre startups bruger Snips et gamified system, hvor brugerne rangeres på et leaderboard.
interessant for: Brug tilfælde, hvor kvalitetskontrol let kan håndhæves
eksempler:
- DeepMind, Maluuba, AlchemyAPI og mange andre (Se her)
- Vocalik (brugt mekanisk Turk til at undervise i sit program, hvordan folk snakker)
- Snips (beder folk om frit at bidrage med data til forskning)
strategi # 4: User-in-the-loop
en menneskemængde strategi, der fortjener sin egen kategori er user-in-the-loop.Denne tilgang indebærer at designe produkter, der giver de rigtige incitamenter for brugerne til at give data tilbage til systemet. To klassiske eksempler på virksomheder, der har brugt denne tilgang til mange af deres produkter, er Google(autofuldførelse i søgning, Google Translate, spamfiltre osv.) og Facebook (brugere tagging venner i fotos). Brugere er ofte uvidende om, at de giver disse virksomheder mærkede data gratis.
mange startups i maskinlæringsrummet har hentet inspiration fra Google og Facebook ved at skabe produkter med en fejltolerant bruger, der eksplicit opfordrer brugerne til at rette maskinfejl. Særligt bemærkelsesværdige arere og Duolingo (begge grundlagt af Luis von Ahn). Andre eksempler omfatter Unbabel, Wit.ai og Mapillary.
interessant for: Forbrugercentrerede startups med konstant brugerinteraktion
eksempler:
- Unbabel (community translators correct machine-genererede oversættelser)
- Wit.ai (forudsat dashboard / API for brugere at rette oversættelsesfejl)
- Mapillary (brugere kan korrigere maskingenereret trafikskiltdetektering)
strategi # 5: Side business
en strategi, der synes at være særlig populær blandt computer vision startups, er at tilbyde en gratis, domænespecifik mobilapp, der er målrettet mod forbrugere. Clarifai, HyperVerge og Madbits (erhvervet af kvidre i 2014) har alle forfulgt denne strategi ved at tilbyde foto apps, der indsamler yderligere billeddata for deres kerneforretning.
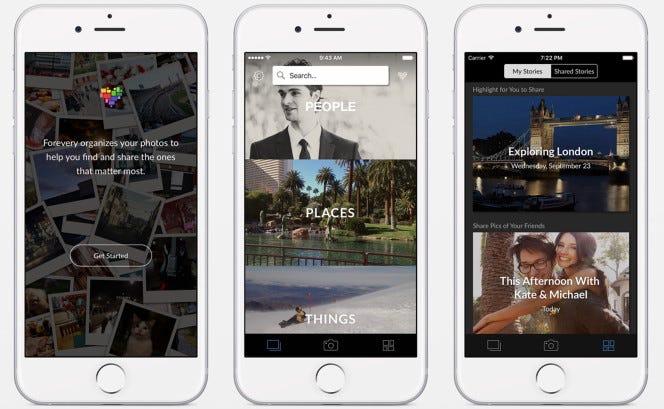
denne strategi er ikke helt uden risiko (når alt kommer til alt koster det tid og penge at udvikle og promovere en app med succes). Startups skal også sikre, at de skaber en stærk nok brugssag, der tvinger brugerne til at opgive deres data, selvom tjenesten mangler fordelene ved datanetværkseffekter i starten.
interessant for: Enterprise startups / vandrette platforme
eksempler:
- Clarifai (Forevery, foto opdagelse app)
- HyperVerge (Sølv, foto organisation app)
- Madbits (Momentsia, foto collage app)