tento článek je zaměřen na učení, jak je navrženo jádro mikrokontroléru, a je určen pouze pro vzdělávací použití. Prosím navštivte www.zilog.com a zkontrolujte produktovou řadu výrobce a vyberte mikrokontrolér, který vyhovuje vašim potřebám projektu (z osmibitových přídavků Z8! a eZ80 chválí 32bitový ARM Cortex-M3 založený ZNEO32! který zahrnuje pokročilé funkce Řízení motoru).
můj milostný vztah s mikrokontroléry a mikroprocesory začal v roce 1988, když jsem pracoval na technickém titulu na CEFET-PR (čtyřletá Brazilská střední / technická škola a univerzita se sídlem v Curitibě). Začal jsem tím, že jsem se naučil základy při zkoumání klasického Zilogu Z-80 (obrázek 1a).

obrázek 1A. Zilog Z-80A (s laskavým svolením Wikimedia Commons).
rychlý posun vpřed prostřednictvím kariéry programování, která zahrnovala tvorbu některých knih o programování mikrokontrolérů (viz zdroje), zahájení malého designového domu (ScTec) a dokončení postgraduálního programu na CEFET-SC (další Brazilská univerzita se sídlem ve Florianopolisu). To bylo v roce 2008, kdy jsem měl větší kontakt s programovatelnou logikou a VHDL a moje zvědavost vyvrcholila. O několik let později v roce 2016 jsem našel velmi cenově dostupnou sadu FPGA (Field-Programmable Gate Array) a rozhodl jsem se jí dát šanci a začal se dozvědět více o technologii FPGA.
co by bylo lepší než navrhnout softcore, abyste se dozvěděli více o VHDL (vhsic hardware description language), FPGA a samotných mikroprocesorových jádrech? Nakonec jsem si vybral moderního příbuzného Z-80: přídavek Zilog Z8! (také znám jako eZ8; obrázek 1b).

obrázek 1B. Zilog eZ8.
je to osmibitové jádro mikrokontroléru s jednoduchou — ale výkonnou-instrukční sadou a velmi pěkným debuggerem na čipu. Se svým lehkým IDE (integrated development environment) a volným kompilátorem ANSI C je to vynikající projekt, který se učí (a také učí) o vestavěných systémech.
než se ponoříme do hlubin jádra, VHDL a FPGA, podívejme se na přídavek Zilog Z8! funkce.

obrázek 1C. FPz8 na FPGA.
Zilog Z8 Encore!
eZ8 je osmibitová rodina mikrokontrolérů založená na úspěšné rodině Zilog Z8 a na velkém dědictví z-80. Je vybaven Harvard CISC stroj s až 4,096 bajtů RAM (registr souborů a speciální funkce Registry oblast), až 64 KB programové paměti (obvykle Flash paměti), a až 64 KB datové paměti (RAM). Jádro eZ8 také obsahuje vektorovaný řadič přerušení s programovatelnou prioritou a debugger na čipu, který komunikuje s hostitelským počítačem pomocí asynchronní sériové komunikace. Tyto mikrokontroléry jsou vybaveny velmi pěknou periferní sadou, od univerzálních 16bitových časovačů až po časovače řízení motoru, od více UART (IrDA ready) až po zařízení USB a mnoho dalšího (navštivte www.zilog.com zkontrolovat celou produktovou řadu).
jedním z hlavních rysů programovacího modelu eZ8 je nedostatek pevného akumulátoru. Místo toho může kterákoli z 4 096 možných adres RAM fungovat jako akumulátory. CPU považuje svou hlavní RAM (soubor a SFRs – speciální funkční registry-oblast) za velkou sadu registrů CPU. Za tímto účelem je RAM rozdělena do registračních skupin (každá má 256 skupin po 16 pracovních registrech). Instrukce obvykle funguje v rámci jedné pracovní skupiny registrů, která je vybrána SFR s názvem RP (register pointer). Všimněte si, že všechny SFR jsou umístěny na poslední stránce paměti RAM(adresy začínající od 0xF00 do 0xFFF).
pokud jde o instrukční sadu, existuje 83 různých instrukcí rozdělených do dvou stránek opcode. Obsahuje obvyklé pokyny pro základní operace, jako je sčítání, odčítání, logické operace, pokyny pro manipulaci s daty, pokyny pro řazení, pokyny pro změnu toku, některé 16bitové pokyny, bitové testování a manipulace, násobení 8×8 atd.
oblast paměti programu je uspořádána tak, aby první adresy byly věnovány zvláštním účelům. Adresy 0x0000 a 0x0001 jsou určeny pro možnosti konfigurace; adresy 0x0002 a 0x0003 ukládají resetovací vektor; a tak dále. Tabulka 1 ukazuje organizaci paměti programu.
| 0x0000 | Option bytes |
| 0x0002 | Reset vector |
| 0x0004 | WDT vector |
| 0x0006 | Illegal instruction vector |
| 0x0008 to 0x0037 | Interrupt vectors |
| 0x0038 to 0xFFFF | User program memory area |
TABLE 1. Simplified program memory organization.
Některá zařízení obsahují také druhý datový prostor (až 65 536 adres), ke kterému lze přistupovat pouze pomocí pokynů LDE/LDEI. Tato oblast může být použita k ukládání méně používaných dat (protože čtení/zápis do ní je pomalejší než oblast RAM/SFR).
FPz8
první implementace FPz8 používá velmi konzervativní a pevně zapojený návrhový přístup se dvěma hlavními sběrnicemi: jednou pro programovou paměť a druhou pro registrovou paměť. Protože jsem se rozhodl nezahrnovat oblast datové paměti, instrukce LDE/LDEI nejsou implementovány.
programové paměťové sběrnice obsahují 16bitovou instrukční adresovou sběrnici (IAB), osmibitovou instrukční datovou sběrnici (IDB pro čtení dat z programové paměti), osmibitovou instrukční zapisovací datovou sběrnici (IWDB pro zápis dat do programové paměti) a signál PGM_WR, který řídí zápis do programové paměti. FPz8 obsahuje 16 384 bajtů programové paměti implementované pomocí synchronní blokové paměti RAM (což znamená, že při vypnutí zařízení dojde ke ztrátě obsahu programové paměti).
pět sběrnic registrů se skládá ze tří pro oblast registru souborů (Uživatelská paměť RAM) a dalších dvou určených pro speciální funkční registry. K dispozici je hlavní 12bitová adresová sběrnice registru souborů (FRAB), osmibitová vstupní datová sběrnice registru souborů (FRIDB), osmibitová výstupní datová sběrnice registru souborů (FRODB), osmibitová vstupní datová sběrnice registru (RIDB) a nakonec osmibitová výstupní datová sběrnice registru (RODB) pro zápis do SFRs. FPz8 obsahuje 2 048 bajtů uživatelské paměti RAM implementované pomocí synchronní blokové paměti RAM.
Obrázek 2 ukazuje blokové schéma FPz8; můžete vidět CPU, dvě paměťové jednotky (jedna pro ukládání programů a druhá pro ukládání dat) a také externí modul časovače.
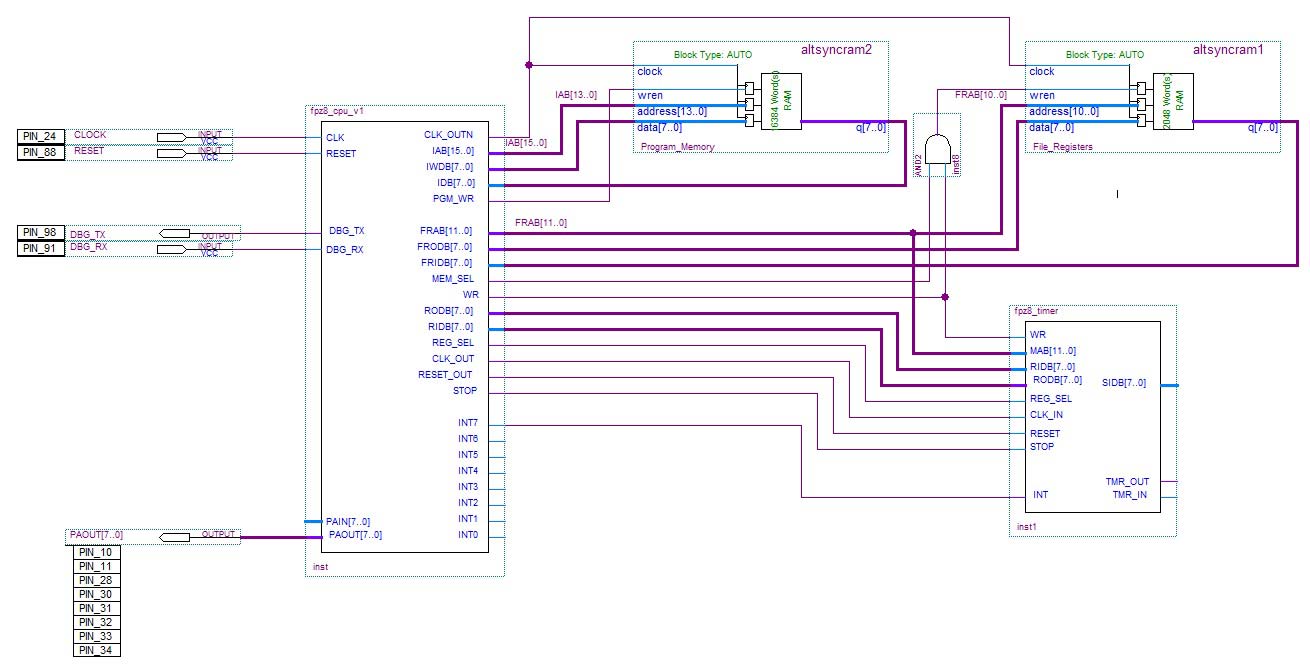
obrázek 2. FPz8 blokové schéma.
Všimněte si, že nepoužívám obousměrné sběrnice pro žádné propojení v tomto projektu. Jednosměrné autobusy jsou jednodušší, i když jsou méně prostorově efektivní.
popis VHDL FPz8 je velký a trochu složitý, takže jeho provoz rozdělím na některé moduly, abych usnadnil porozumění:
- Instruction queueing engine
- Instruction decoding
- Interrupt processing
- Debugger
Instruction Queueing Engine
načítání instrukcí je primárním úkolem pro jakýkoli procesor. Harvardská Architektura FPz8 umožňuje souběžné načítání a přístup k datům (díky samostatným sběrnicím pro instrukce a data). To znamená, že CPU může načíst novou instrukci, zatímco jiný čte nebo zapisuje do datové paměti.
eZ8 má instrukční slovo s proměnnou délkou (délka instrukce se pohybuje od jednoho bajtu až po pět bajtů); některé pokyny jsou zdlouhavé, ale běží rychleji než jiné. Tímto způsobem má instrukce BRK délku jednoho bajtu a běží ve dvou cyklech, zatímco LDX IM, ER1 je dlouhý čtyři bajty a běží ve dvou hodinových cyklech.
jak tedy můžeme úspěšně dekódovat všechny tyto pokyny? Mechanismus, který udržuje načítání bajtů z programové paměti a jejich ukládání do osmibajtového pole:
if (CAN_FETCH= ‚1‘) pak
if (IQUEUE.FETCH_STATE=F_ADDR) pak
FETCH_ADDR: = PC;
IAB < = PC;
IQUEUE.WRPOS: = 0;
IQUEUE.RDPOS: = 0;
IQUEUE.CNT := 0;
IQUEUE.FETCH_STATE: = F_READ;
else
if (IQUEUE.FULL= ‚0‘) pak
IQUEUE.FRONTA (IQUEUE.WRPOS): = IDB;
FETCH_ADDR: = FETCH_ADDR + 1;
IAB < = FETCH_ADDR;
IQUEUE.WRPOS: = IQUEUE.WRPOS + 1;
IQUEUE.CNT: = IQUEUE.CNT + 1;
konec if;
konec if;
konec if;
if (IQUEUE.CNT=7) pak IQUEUE.FULL:= ‚1‘; else IQUEUE.FULL:= ‚0‘;
konec if;
výpis 1. Motor fronty instrukcí.
načítání je řízeno hlavním povolovacím signálem (CAN_FETCH), který může být v některých zvláštních případech zakázán (zpracování přerušení, instrukce LDC / LDCI nebo přístup debuggeru). K dispozici je také struktura (IQUEUE), která ukládá několik vnitřních parametrů (stav načítání, ukazatele pro čtení a zápis, samotné pole fronty, čítač a Plný indikátor).
čítač fronty (CNT) se používá k identifikaci počtu bajtů dostupných pro použití (čtení) ve frontě. Fáze dekodéru používá toto číslo k ověření, že požadovaný počet bajtů pro instrukci je již ve frontě k dispozici.
dekódování instrukcí
zde se děje skutečná magie. Dekodér instrukcí čte opcodes z fronty instrukcí a převádí je do odpovídajících operací.
návrh dekodéru instrukce začal zjišťováním vztahu mezi všemi pokyny a režimy adresování. Na první pohled je snadné vidět, že některé pokyny (obrázek 3) jsou seskupeny podle sloupců (DJNZ, JR cc, X, LD r1, IM, JP cc, DA A INC r1). Dekódování instrukce INC r1 je jednoduché: v těchto jednobajtových instrukcích určuje vysoký nibble zdrojový / cílový registr a dolní nibble určuje samotnou instrukci (0xE).
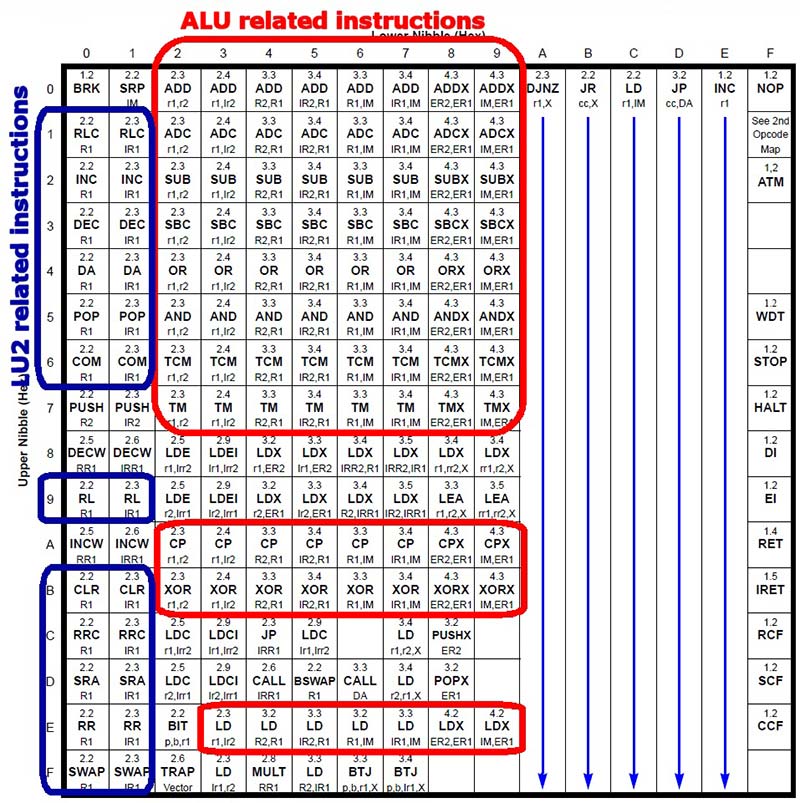
obrázek 3. Opcodes podle skupin.
většinu pokynů lze klasifikovat podle některých základních pravidel:
- sloupce (dolní okusování opcode) obvykle určují režim adresování: Instrukce ve sloupci 0x9 například většinou používají adresovací režim IM, ER1 a jsou dlouhé čtyři bajty (druhý bajt je okamžitý operand a dva poslední bajty jsou Cílová rozšířená adresa).
- řádky (vyšší okusování opcode) obvykle specifikují operaci: pokyny řádku 0x0 jsou většinou operace sčítání; pokyny řádku 0x2 jsou většinou operace odčítání atd.
pokud se podíváme na řádek 0x1, vidíme, že sloupce 0x0 a 0x1 jsou pokyny RLC a sloupce 0x2 až 0x9 jsou pokyny ADC. Můžeme tedy navrhnout ALU, který vezme nibble jako vstup (vyšší nibble z opcode) a podle toho jej dekóduje. I když by to fungovalo pro sloupce 0x2 až 0x9, pro první dva sloupce bychom potřebovali jiný přístup.
proto jsem nakonec napsal dvě jednotky: jednu ALU, která se soustředí na většinu aritmetických a logických instrukcí; a druhou jednotku (logická jednotka 2 nebo LU2), která provádí další operace zobrazené ve sloupcích 0x0 a 0x1 (ne všechny operace vidět na těchto sloupcích jsou prováděny LU2). Operační kódy pro ALU i LU2 byly vybrány tak, aby odpovídaly řádkům opcode znázorněným na obrázku 3.
dalším důležitým detailem je, že všechny instrukce ve stejném sloupci a skupině mají stejnou velikost v bajtech, takže je lze dekódovat ve stejné sekci dekodéru.
návrh dekodéru využívá velký konečný stavový stroj (FSM), který postupuje při každém tikání hodin. Každá instrukce začíná v CPU_DECOD stat. Zde dekodér skutečně dekóduje opcodes, připravuje sběrnice a interní podpůrné signály a kroky k dalším stavům provádění. Mezi všemi těmito stavy jsou dva široce používány mnoha instrukcemi: CPU_OMA a CPU_OMA2. Uhodnete proč? Pokud jste řekl, protože se vztahují k ALU a LU2, máte naprostou pravdu!
OMA je zkratka pro jeden přístup do paměti a je to poslední stav pro všechny pokyny související s ALU (ADD, ADC, ADDX, ADCX, SUB, SBC, SUBX, SBCX, OR, ORX, ANDX, XOR, XORX, CP, CPC, TCM, TCMX, TM, TMX a některé varianty LD a LDX). Na druhou stranu, CPU_OMA2 je poslední stav pro všechny pokyny související s LU2 (RLC, INC, DEC ,DA, COM, RL, CLR, RRC, SRA, SRL, RR a SWAP).
nyní se podívejme do stavu CPU_DECOD. Viz obrázek 4.
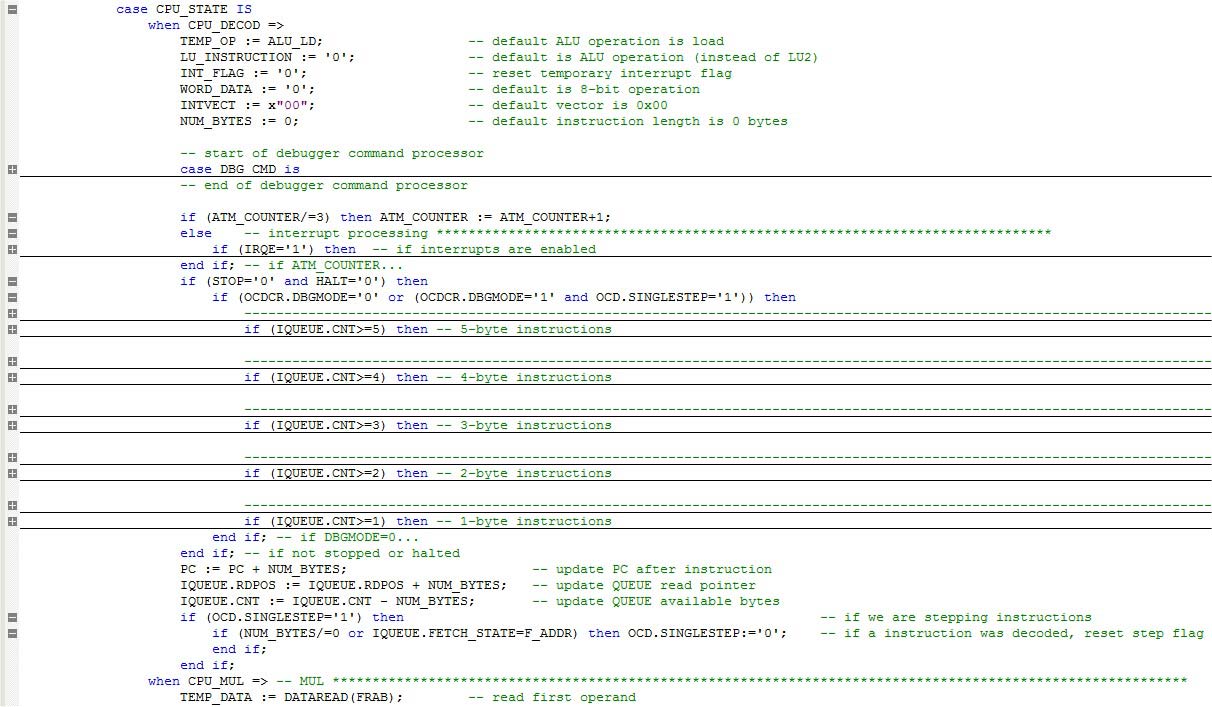
obrázek 4. Stav CPU_DECOD.
ve stavu CPU_DECOD vidíme, že se odehrává mnoho akcí. Na začátku jsou některé dočasné proměnné inicializovány do výchozí podmínky. Všimněte si, že NUM_BYTES je velmi důležité, protože určuje, kolik bajtů bylo spotřebováno dekodérem instrukce. Jeho hodnota se používá v poslední části této fáze pro zvýšení PC (počítadlo programů), posunutí ukazatele čtení fronty a snížení počtu dostupných bajtů ve frontě.
po sekci inicializace vidíme sekci zpracování přerušení. Je zodpovědný za detekci jakýchkoli čekajících přerušení a odpovídajícím způsobem připravuje CPU. Budu to pokrývat v další části.
skutečný blok dekódování instrukcí kontroluje, zda není aktivní režim nízké spotřeby a také, zda je režim debuggeru vypnutý (OCDCR .DBGMODE=0). Nebo, zatímco v režimu ladění, byl vydán příkaz single step debug (OCDCR.DBGMODE=1 a OCD.SINGLE_STEP=1). Poté zkontroluje dostupné bajty ve frontě a pokračuje s dekódováním.
některé instrukce (většinou ty singlebyte) jsou dokončeny ve stavu CPU_DECOD, zatímco jiné potřebují více stavů, dokud nejsou zcela dokončeny.
Všimněte si, že některé dekódování instrukcí mohou využívat několik funkcí a postupů napsaných speciálně pro FPz8:
- DATAWRITE-tento postup připravuje autobusy pro operaci zápisu. Vybírá, zda je cílem interní SFR, externí SFR nebo umístění uživatelské paměti RAM.
- DATAREAD-jedná se o reciproční funkci pro DATAWRITE. Používá se ke čtení zdrojové adresy a automaticky zvolí, zda se jedná o interní SFR, externí SFR nebo umístění uživatelské paměti RAM.
- CONDITIONCODE-Používá se pro podmíněné instrukce (například JR a JP). Vezme čtyřbitový stavový kód, otestuje jej a vrátí výsledek.
- ADDRESSER4, ADDRESSER8 a ADDRESSER12 – tyto funkce vracejí 12bitovou adresu ze čtyřbitového, osmibitového nebo 12bitového zdroje. Používají obsah registru RP ke generování konečné 12bitové adresy. ADDRESSER8 a ADDRESSER12 také zkontrolují, zda nedošlo k úniku režimu adresování.
- ADDER16-Jedná se o 16bitovou sčítačku pro výpočet offsetu adresy. Trvá osmibitový podepsaný operand, znak jej rozšíří, přidá jej na 16bitovou adresu a vrátí výsledek.
- ALU a LU2-ty byly diskutovány dříve a provádějí většinu aritmetických a logických operací.
zpracování přerušení
jak jsem již řekl, eZ8 má vektorovaný řadič přerušení s programovatelnou prioritou. Nejprve jsem si myslel, že tato sekce nebude tak obtížná, protože přerušení není velký problém, že? No, když jsem začal přijít na to, jak dělat všechny potřebné úkoly (ukládání kontextu, vektorování, správa priorit atd.), Uvědomil jsem si, že to bude těžší, než jsem si poprvé myslel. Po několika hodinách jsem přišel s aktuálním designem.
systém přerušení FPz8 byl nakonec jednoduchý. Má osm vstupů (INT0 až INT7); globální povolení přerušení (irqe bit umístěný v irqctl registru); dva registry pro nastavení priority (IRQ0ENH a IRQ0ENL); a jeden registr pro příznaky přerušení (IRQ0). Návrh využívá vnořený řetězec IF, který generuje vektorovou adresu při detekci události přerušení týkající se povoleného přerušení.
obrázek 5 ukazuje komprimovaný pohled na systém přerušení. Poznámka: existuje první if příkaz se symbolem ATM_COUNTER. Jedná se o jednoduchý čítač používaný instrukcí ATM (zakáže přerušení pro tři instrukční cykly, což umožňuje atomové operace).
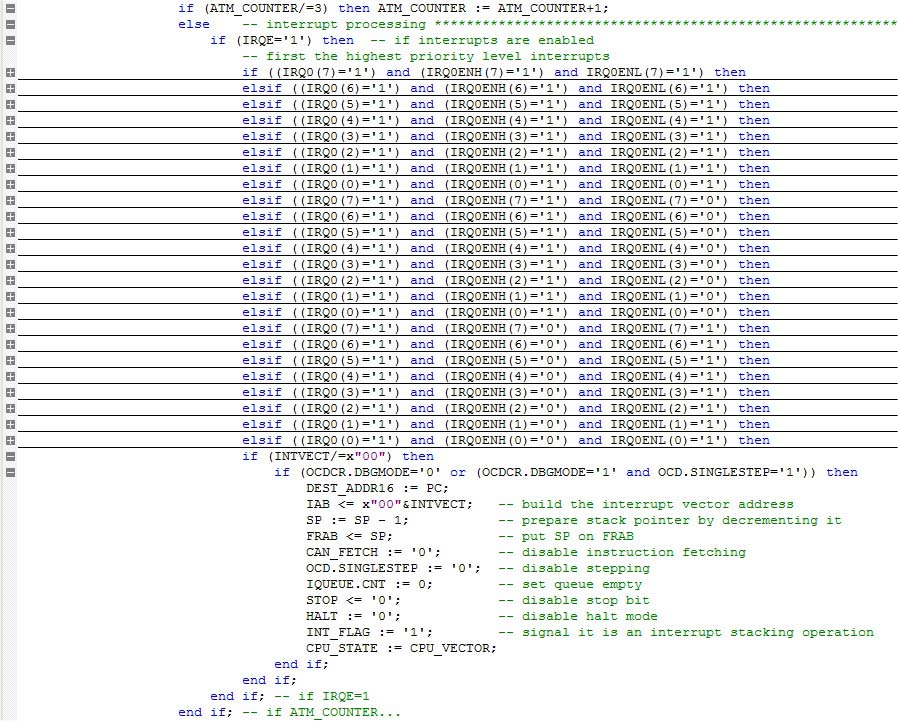
obrázek 5. FPz8 přerušovací systém.
poslední komentář k přerušení: Registr příznaků přerušení (IRQ0) vzorkuje vstupy přerušení každé stoupající hraně systémových hodin. Existují také dvě proměnné vyrovnávací paměti (IRQ0_LATCH a OLD_IRQ0), které ukládají aktuální a poslední stav příznaků. To umožňuje detekci hran přerušení a také synchronizuje Externí vstupy s interními hodinami (FPGA nefungují dobře s asynchronními interními signály).
on-Chip Debugger
Toto je pravděpodobně nejchladnější funkce tohoto softcore, protože umožňuje komerční integrované vývojové prostředí (IDE; Zilog je ZDS-II) pro komunikaci, programování a ladění softwaru běžícího na FPz8. Debugger na čipu (OCD) se skládá z UART s možností autobaud a k němu připojeného příkazového procesoru. UART provádí sériovou komunikaci s hostitelským počítačem a doručuje příkazy a data do stavového stroje debugger, který zpracovává debugovací příkazy (FSM pro zpracování příkazů debugger je umístěn uvnitř stavu CPU_DECOD).

obrázek 6. Debugger na čipu UART (všimněte si synchronizátoru DBG_RX).
můj návrh OCD implementuje téměř všechny příkazy dostupné na skutečném hardwaru, s výjimkou příkazů souvisejících s datovou pamětí (ladicí příkazy 0x0C a 0x0D); čítač běhu čtení (0x3); a paměť programu čtení CRC (0x0E).
jedna věc, kterou bych chtěl zdůraznit, je potřeba péče při práci s asynchronními signály uvnitř FPGA. Můj první návrh to nezohlednil při zpracování vstupního signálu DBG_RX. Výsledek byl naprosto divný. Můj návrh pracoval bezchybně v simulaci. Stáhl jsem ji do FPGA a začal hrát s debug serial interface pomocí sériového terminálu (Moje FPGA deska má vestavěný serial-USB převodník).
k mému překvapení, zatímco většinu času jsem mohl úspěšně odesílat příkazy a přijímat očekávané výsledky, někdy by návrh jednoduše zamrzl a přestal reagovat. Měkký reset by přiměl věci vrátit se do správného fungování,ale to mě zaujalo. Co se dělo?
po mnoha testech a nějakém Googlování jsem zjistil, že to pravděpodobně souvisí s asynchronními hranami sériového vstupního signálu. Pak jsem zahrnoval kaskádovou západku pro synchronizaci signálu s mými interními hodinami a všechny problémy byly pryč! To je těžký způsob, jak zjistit, že musíte vždy synchronizovat externí signály před jejich krmení do složité logiky!
musím říci, že ladění a zdokonalování kódu debuggeru bylo nejtěžší částí tohoto projektu; hlavně proto, že interaguje se všemi ostatními subsystémy včetně autobusů, dekodéru a fronty instrukcí.
syntéza a testování
po úplném zkompilování (použil jsem Quartus II V9.1 sp2) použilo jádro FPz8 4900 logických prvků, 523 registrů, 147 456 bitů paměti na čipu a jeden vložený devítibitový multiplikátor. Celkově FPz8 využívá 80% dostupných zdrojů EP4CE6. I když je to hodně, stále existuje několik logických prvků 1,200 pro periferie (můj jednoduchý 16bitový časovač přidává přibližně logické prvky 120 a registry 61). Dokonce se hodí na nejmenší FPGA Cyclone IV-EP4CE6-což je ten, který je namontován na nízkonákladové mini desce, kterou jsem zde použil (Obrázek 7).

obrázek 7. Altera Cyclone IV EP4CE6 mini deska.
funkce mini desky (spolu se zařízením EP4CE6): sériová konfigurační paměť EPCS4 (namontovaná na spodní straně); čip FTDI serial-to-USB converter a modul krystalového oscilátoru 50 MHz; některá tlačítka; LED diody; a záhlaví pinů pro přístup k pinům FPGA. Neexistuje žádný integrovaný USB-Blaster (pro programování FPGA), ale balíček, který jsem koupil, obsahoval také externí programovací klíč.
pokud jde o testy v reálném světě, Netřeba dodávat, že FPz8 nefungoval poprvé! Po přemýšlení a čtení výstupních zpráv kompilátoru jsem zjistil, že to byl pravděpodobně problém s načasováním. Toto je velmi běžné dilema při navrhování s programovatelnou logikou, ale protože to byl můj druhý návrh FPGA vůbec, nevěnoval jsem tomu dostatečnou pozornost.
při kontrole zpráv o analýze časování jsem viděl varování, že maximální hodiny by měly být kolem 24 MHz. Nejprve jsem se pokusil pomocí děliče o 2 vygenerovat hodiny procesoru 25 MHz, ale nebylo to spolehlivé. Pak jsem použil dělič-by-3. Všechno začalo fungovat perfektně!
to je důvod, proč FPz8 v současné době běží na 16.666 MHz. Je možné dosáhnout vyšších rychlostí pomocí jedné z interních PLL pro násobení / rozdělení hlavních hodin, aby se výsledné hodiny dostaly nižší než 24 MHz, ale vyšší než 16.666 MHz.
programování a ladění
pomocí FPz8 je velmi jednoduché a přímočaré. Jakmile je návrh stažen do FPGA, CPU začne spouštět jakýkoli program načtený do paměti. Můžete zadat soubor hex a pomocí Správce zásuvných modulů MegaWizard změnit Inicializační soubor paměti programu. Tímto způsobem se kód aplikace spustí po signálu resetování.
IDE Zilog ZDS-II můžete použít k zápisu sestavy nebo kódu C a generování potřebných souborů hex (obvykle si jako cílové zařízení vyberu z8f1622, protože má také 2 KB RAM a 16 KB programové paměti). Díky on-chip debuggeru je také možné pomocí ZDS-II IDE stáhnout kód do FPz8 pomocí sériového debug připojení (v našem případě USB).
před připojením se ujistěte, že nastavení debuggeru je stejné jako na obrázku 8. Zrušte zaškrtnutí možnosti „použít vymazání stránky před blikáním“ a jako aktuální ladicí nástroj vyberte „SerialSmartCable“. Nezapomeňte také zkontrolovat, zda je virtuální COM port FTDI správně vybrán jako debug port (použijte tlačítko Nastavení). Můžete také nastavit požadovanou rychlost komunikace; 115,200 bps pro mě funguje velmi dobře.
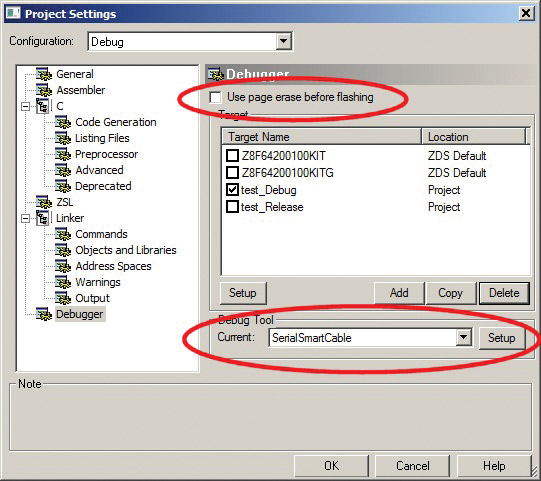
OBRÁZEK 8. Nastavení debuggeru.
Všimněte si, že při připojení k FPz8 zobrazí IDE ZDS-II varovnou zprávu informující, že cílové zařízení není stejné jako projekt. To se děje proto, že jsem neimplementoval některé oblasti paměti ID. Stačí ignorovat varování a pokračovat v ladění relace.
po úspěšném stažení kódu můžete spustit aplikaci (tlačítko GO), krokové pokyny, zkontrolovat nebo upravit registry, nastavit zarážky atd. Stejně jako u jiných dobrých debuggerů můžete například vybrat registr PAOUT (pod skupinou porty) a dokonce změnit stav LED připojených k PAOUT.
některé jednoduché příklady C kódu lze nalézt v stahování.
jen mějte na paměti, že FPz8 má Volatilní programovou paměť. Při vypnutí FPGA se tedy ztratí jakýkoli program, který je do něj stažen.
uzavření
tento projekt mi trvalo několik týdnů, než jsem dokončil, ale bylo příjemné zkoumat a navrhnout jádro mikrokontroléru.
doufám, že tento projekt může být užitečný pro každého, kdo se chce dozvědět o základech výpočetní techniky, mikrokontrolérech, vestavěném programování a/nebo VHDL. Věřím, že — pokud je spárován s nízkonákladovou deskou FPGA-FPz8 může poskytnout fantastický nástroj pro učení(a výuku). Bavte se! NV
CEFET-PR:
www.utfpr.edu.br
ScTec:
www.sctec.com.br
HCS08 Unleashed:
https://www.amazon.com/HCS08-Unleashed-Designers-Guide-Microcontrollers/dp/1419685929
Zilog eZ8 CPU Manual (UM0128):
www.zilog.com/docs/UM0128.pdf
Zilog Z8F64xx Product Specification (PS0199):
www.zilog.com/docs/z8encore/PS0199.pdf
Zilog ZDS II IDE User Manual (UM0130):
www.zilog.com/docs/devtools/UM0130.pdf
Zilog ZDS-II Software Download:
https://www.zilog.com/index.php?option=com_zcm&task=view&soft_id=7&Itemid=74
Zilog Microcontroller Product Line:
http://zilog.com/index.php?option=com_product&task=product&businessLine=1&id=2&parent_id=2&Itemid=56
Project Files available at:
https://github.com/fabiopjve/VHDL/tree/master/FPz8
FPz8 at Opencores.org:
http://opencores.org/project,fpz8