Autor: Moritz Mueller-Freitag, Eleven Strategy.
„nepřiměřená účinnost“ dat pro aplikace strojového učení byla v průběhu let široce diskutována (viz zde, zde a zde). Bylo také navrženo, že mnoho významných průlomů v oblasti umělé inteligence nebylo omezeno algoritmickým pokrokem, ale dostupností vysoce kvalitních datových souborů (viz zde). Společným vláknem, které prochází těmito diskusemi, je to, že data jsou důležitou součástí nejmodernějšího strojového učení.
přístup k vysoce kvalitním tréninkovým datům je zásadní pro začínající podniky, které používají strojové učení jako základní technologii svého podnikání. Zatímco mnoho algoritmů a softwarových nástrojů je otevřených zdrojů a sdílených v celé výzkumné komunitě, dobré datové sady jsou obvykle proprietární a těžko sestavitelné. Vlastnictví velkého datového souboru specifického pro doménu se proto může stát významným zdrojem konkurenční výhody, zejména pokud startupy mohou jumpstartovat efekty datové sítě (situace, kdy více uživatelů → více dat → chytřejší algoritmy → lepší produkt → více uživatelů).
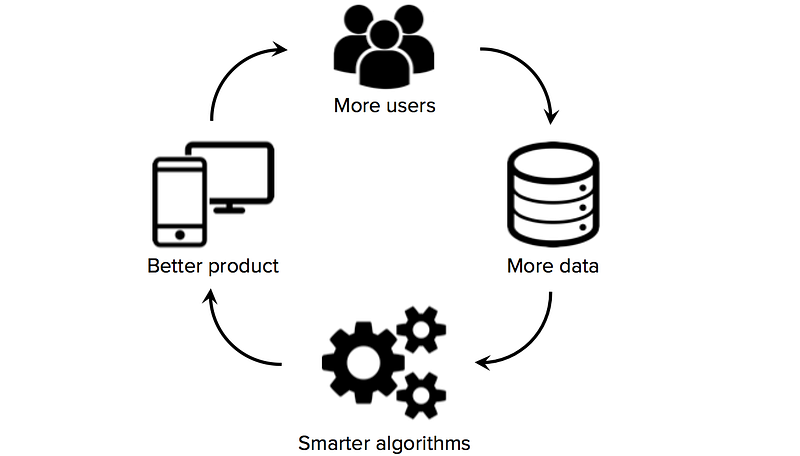
v důsledku toho je jedním z klíčových strategických rozhodnutí, která musí startupy strojového učení učinit, jak vytvořit vysoce kvalitní datové sady pro výcvik jejich učebních algoritmů. Bohužel, startupy mají na začátku často omezená nebo žádná označená data, situace, která zakladatelům brání v dosažení významného pokroku při vytváření produktu založeného na datech. Proto stojí za to prozkoumat strategie získávání dat od samého počátku, než najmete tým data science nebo vybudujete nákladnou základní infrastrukturu.
startupy mohou překonat problém studeného startu při získávání dat mnoha způsoby. Volba datové strategie / zdroje obvykle jde ruku v ruce s výběrem obchodního modelu, zaměřením startupu (spotřebitel nebo podnik, horizontální nebo vertikální atd.) a finanční situace. Následující seznam strategií, i když ani vyčerpávající, ani vzájemně se nevylučující, dává smysl pro širokou škálu dostupných přístupů.
strategie # 1: ruční práce
budování dobrého proprietárního datového souboru od nuly téměř vždy znamená dát hodně up-front, lidské úsilí do získávání dat a provádění manuálních úkolů,které se nemění. Příkladů startupů, které na začátku používaly hrubou sílu, je spousta. Například mnoho chatbot startupů zaměstnává lidské „AI trenéry“, kteří ručně vytvářejí nebo ověřují předpovědi, které jejich virtuální agenti dělají (s různou mírou úspěchu a vysokou mírou fluktuace zaměstnanců). Dokonce i tech giganti se uchylují k této strategii: všechny odpovědi Facebook M jsou přezkoumány a upraveny týmem dodavatelů.

použití hrubé síly k ručnímu označení datových bodů může být úspěšnou strategií, pokud se v určitém okamžiku objeví efekty datové sítě, takže lidé již nebudou škálovat stejným tempem jako zákaznická základna. Jakmile se systém AI zlepšuje dostatečně rychle, nespecifikované odlehlé hodnoty se stávají méně častými a počet lidí, kteří provádějí ruční označování, může být snížen nebo udržován konstantní.
zajímavé pro: více či méně každé spuštění strojového učení
příklady:
- mnoho startupů chatbot (včetně Magic, GoButler, x.ai a Clara)
- MetaMind (ručně shromážděné a označené datové sady pro klasifikaci potravin)
- Stavební Radar (zaměstnanci / stážisté ručně označují obrázky budov)
strategie #2: zúžit doménu
většina startupů se bude snažit shromažďovat data přímo od uživatelů. Úkolem je přesvědčit rané osvojitele, aby produkt používali dříve, než se výhody strojového učení plně nastartují (protože data jsou potřebná především k trénování a doladění algoritmů). Jedním ze způsobů, jak obejít tento catch-22, je drasticky zúžit problémovou doménu (a v případě potřeby rozšířit rozsah později). Jak říká Chris Dixon: „množství dat, které potřebujete, je relativní k šíři problému, který se snažíte vyřešit.“
dobrými příklady výhod úzké domény jsou opět chatboty. Startupy v tomto segmentu si mohou vybrat mezi dvěma strategiemi go-to-market: mohou vytvářet horizontální asistenty-roboty, které mohou pomoci s velkým počtem otázek a okamžitých požadavků (příklady jsou viv, Magic,Awesome, Maluuba a Jam). Nebo mohou vytvořit vertikální asistenty-roboty, kteří se snaží vykonávat jednu konkrétní, dobře definovanou práci velmi dobře (příklady jsou x.ai, Clara, DigitalGenius, Kasisto, Meekan – a více recentlyGoButler / Angel. ai). Zatímco oba přístupy jsou platné, sběr dat je dramaticky jednodušší pro startupy, které řeší problémy s uzavřenou doménou.
zajímavé pro: vertikálně integrované podniky
příklady:
- vysoce specializované vertikální chatboty (například x.ai, Clara nebo GoButler)
- Hluboká genomika (používá hluboké učení ke klasifikaci/interpretaci genetických variant)
- kvantifikovaná kůže (používá selfies zákazníků k analýze kůže člověka)
strategie č. 3: Crowdsourcing / Outsourcing
namísto použití kvalifikovaných zaměstnanců (nebo stážistů) k ručnímu shromažďování nebo označování dat mohou startupy tento proces také crowdsource. Platformy jako Amazon Mechanical Turk nebo CrowdFlower nabízejí způsob, jak vyčistit chaotická a neúplná data pomocí Online Pracovní síly milionů lidí. Například VocalIQ (získaný společností Apple v roce 2015) použil Amazonův mechanický Turk k tomu, aby krmil svého digitálního asistenta tisíci uživatelských dotazů. Pracovníci mohou být také externě zaměstnáni jinými nezávislými dodavateli (jak to dělá cyclara nebo Facebook M). Nezbytnou podmínkou pro použití tohoto přístupu je, že úkol lze jasně vysvětlit a není příliš dlouhý / nudný.

další taktikou je motivovat veřejnost k dobrovolnému přispívání dat. Příkladem je Snips, pařížský startup AI, který používá tento přístup k získání určitého typu dat (potvrzovací e-maily pro restaurace, hotely a letecké společnosti). Stejně jako ostatní startupy, Snips používá gamified systém, kde jsou uživatelé zařazeni do žebříčku.
zajímavé pro: Použijte případy, kdy lze kontrolu kvality snadno vynucovat
příklady:
- DeepMind, Maluuba, AlchemyAPI a mnoho dalších (viz zde)
- VocalIQ (používá mechanický Turk učit svůj program, jak lidé mluví)
- Snips (žádá lidi, aby volně přispívat data pro výzkum)
strategie #4: User-in-the-loop
crowdsourcingová strategie, která si zaslouží svou vlastní kategorii, je user-in-the-loop.Tento přístup zahrnuje navrhování produktů, které poskytují uživatelům správné pobídky k vrácení dat do systému. Dva klasické příklady společností, které tento přístup použily pro mnoho svých produktů, jsou Google (Automatické doplňování ve vyhledávání, Překladač Google, filtry spamu atd.) a Facebook (uživatelé označující přátele na fotografiích). Uživatelé si často neuvědomují, že těmto společnostem poskytují označená data zdarma.
mnoho startupů v prostoru strojového učení čerpalo inspiraci z Google a Facebook vytvořením produktů s UX odolným proti chybám, které výslovně povzbuzují uživatele k opravě chyb stroje. Zvláště pozoruhodné arere a Duolingo (oba založili Luis von Ahn). Mezi další příklady patří Unbabel, Wit.ai a Mapillary.
zajímavé pro: začínající podniky zaměřené na spotřebitele s neustálou interakcí uživatelů
příklady:
- Unbabel (komunitní překladatelé opravují strojově generované překlady)
- Wit.ai (za předpokladu, dashboard/API pro uživatele opravit chyby překladu)
- Mapillary (uživatelé mohou opravit strojově generované detekce dopravní značky)
strategie # 5: Side business
strategie, která se zdá být obzvláště populární mezi startupy počítačového vidění, je nabídnout bezplatnou mobilní aplikaci specifickou pro doménu, která se zaměřuje na spotřebitele. Clarifai, HyperVerge a Madbits (získané Twitterem v roce 2014) sledují tuto strategii tím, že nabízejí fotografické aplikace, které shromažďují další obrazová data pro své hlavní podnikání.
tato strategie není zcela bez rizika(konec konců to stojí čas a peníze na úspěšný vývoj a propagaci aplikace). Startupy musí také zajistit, aby vytvořily dostatečně silný případ použití, který nutí uživatele, aby se vzdali svých dat, i když služba na začátku postrádá výhody efektů datové sítě.
zajímavé pro: podnikové startupy/horizontální platformy
příklady:
- Clarifai (Forevery, photo discovery app)
- HyperVerge (Silver, photo organization app)
- Madbits (Momentsia, photo collage app)