de Moritz Mueller-Freitag, Eleven Strategy.
„eficacitatea nerezonabilă” a datelor pentru aplicațiile de învățare automată a fost dezbătută pe scară largă de-a lungul anilor (a se vedea aici, aici și aici). De asemenea, s-a sugerat că multe descoperiri majore în domeniul inteligenței artificiale nu au fost constrânse de progresele algoritmice, ci de disponibilitatea seturilor de date de înaltă calitate (a se vedea aici). Firul comun care trece prin aceste discuții este că datele sunt o componentă vitală în realizarea învățării automate de ultimă generație.
accesul la date de instruire de înaltă calitate este esențial pentru startup-urile care folosesc învățarea automată ca tehnologie de bază a afacerii lor. În timp ce mulți algoritmi și instrumente software sunt open source și partajate în comunitatea de cercetare, seturile de date bune sunt de obicei proprietare și greu de construit. Deținerea unui set de date mare, specific domeniului, poate deveni, prin urmare, o sursă semnificativă de avantaj competitiv, mai ales dacă startup-urile pot relansa efectele rețelei de date (situație în care mai mulți utilizatori, mai mulți utilizatori, mai mulți utilizatori, mai mulți utilizatori, mai mulți utilizatori, mai mulți utilizatori, mai mulți utilizatori, mai mulți utilizatori, mai mulți utilizatori, mai mulți utilizatori.
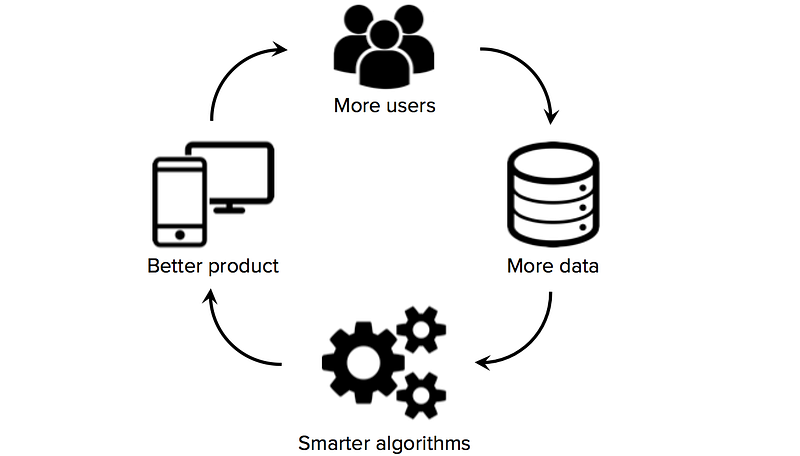
în consecință, una dintre deciziile strategice cheie pe care trebuie să le ia startup-urile de învățare automată este cum să construiască seturi de date de înaltă calitate pentru a-și instrui algoritmii de învățare. Din păcate, startup – urile au adesea date limitate sau deloc etichetate la început, situație care împiedică fondatorii să facă progrese semnificative în construirea unui produs bazat pe date. Prin urmare, merită explorate strategiile de achiziție a datelor de la început, înainte de a angaja echipa de știință a datelor sau de a construi o infrastructură de bază costisitoare.
startup-urile pot depăși problema de pornire la rece a achiziției de date în numeroase moduri. Alegerea strategiei/sursei de date merge de obicei mână în mână cu alegerea modelului de afaceri, concentrarea unui startup (consumator sau întreprindere, orizontală sau verticală etc.) și situația finanțării. Următoarea listă de strategii, deși nu este exhaustivă și nici nu se exclude reciproc, oferă un sens pentru gama largă de abordări disponibile.
strategia # 1: munca manuală
construirea unui set de date de proprietate bun de la zero aproape întotdeauna înseamnă a pune o mulțime de up-front, efort uman în achiziția de date și efectuarea sarcinilor manuale care nu scară. Exemple de startup-uri care au folosit forța brută la început sunt abundente. De exemplu, multe startup-uri de chatbot folosesc „formatori AI” umani care creează sau verifică manual predicțiile pe care le fac agenții lor virtuali (cu diferite grade de succes și o rată ridicată a cifrei de afaceri a angajaților). Chiar și giganții tehnologici recurg la această strategie: toate răspunsurile Facebook M sunt revizuite și editate de o echipă de contractori.

utilizarea forței brute pentru a eticheta manual punctele de date poate fi o strategie de succes, atâta timp cât efectele rețelei de date intră la un moment dat, astfel încât oamenii să nu mai scaleze într-un ritm egal cu baza de clienți. De îndată ce sistemul AI se îmbunătățește suficient de repede, valorile aberante nespecificate devin mai puțin frecvente și numărul de oameni care efectuează etichetarea manuală poate fi scăzut sau menținut constant.
interesant pentru: mai mult sau mai puțin fiecare pornire de învățare automată
Exemple:
- multe startup-uri chatbot (inclusiv Magic, GoButler, x.ai și Clara)
- MetaMind (set de date colectate și etichetate manual pentru clasificarea alimentelor)
- radar de construcție (angajați / stagiari etichetează manual imaginile clădirilor)
strategia # 2: restrângeți domeniul
majoritatea startup-urilor vor încerca să colecteze date direct de la utilizatori. Provocarea este de a convinge early adopters să utilizeze produsul înainte ca beneficiile învățării automate să intre pe deplin (deoarece sunt necesare date în primul rând pentru a instrui și regla fin algoritmii). O modalitate în jurul acestui catch-22 este de a restrânge drastic domeniul problemei (și de a extinde domeniul de aplicare mai târziu, dacă este necesar). După cum spune Chris Dixon: „cantitatea de date de care aveți nevoie este relativă la amploarea problemei pe care încercați să o rezolvați.”
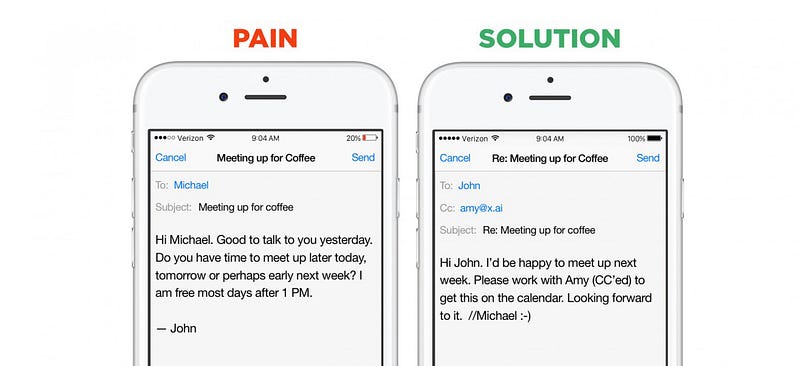
exemple bune ale beneficiilor unui domeniu îngust sunt din nou chatbots. Startup-urile din acest segment pot alege între două strategii go-to — market: pot construi asistenți orizontali-roboți care pot ajuta cu un număr foarte mare de întrebări și solicitări imediate (exemple sunt Viv, Magic,Awesome, Maluuba și Jam). Sau pot crea asistenți verticali-roboți care încearcă să efectueze extrem de bine un loc de muncă specific, bine definit (exemple sunt x.ai, Clara, DigitalGenius, Kasisto, Meekan — și mai recentlyGoButler/Angel.ai). Deși ambele abordări sunt valide, colectarea datelor este dramatic mai ușoară pentru startup-urile care abordează probleme de domeniu închis.
interesant pentru: întreprinderi integrate vertical
Exemple:
- chatbots verticali foarte specializați (cum ar fi x.ai, Clara sau GoButler)
- genomică profundă (folosește învățarea profundă pentru a clasifica/interpreta variantele genetice)
- piele cuantificată (folosește selfie-urile clienților pentru a analiza pielea unei persoane)
strategia # 3: Crowdsourcing / Outsourcing
în loc să utilizeze angajați calificați (sau stagiari) pentru a colecta sau eticheta manual date, startup-urile pot, de asemenea, să crowdsource procesul. Platforme precum Amazon Mechanical Turk sau CrowdFlower oferă o modalitate de a curăța date dezordonate și incomplete folosind o forță de muncă online de milioane de oameni. De exemplu, VocalIQ (achiziționat de Apple în 2015) a folosit Amazon Mechanical Turk pentru a-și alimenta asistentul digital mii de interogări ale utilizatorilor. Lucrătorii pot fi, de asemenea, externalizați prin angajarea altor contractori independenți (așa cum este făcut de cyclara sau Facebook M). Condiția necesară pentru utilizarea acestei abordări este că sarcina poate fi explicată clar și nu este prea lungă/plictisitoare.

o altă tactică este de a stimula publicul să contribuie voluntar la date. Un exemplu este Snips, un startup AI din Paris care folosește această abordare pentru a pune mâna pe un anumit tip de date (e-mailuri de confirmare pentru restaurante, hoteluri și companii aeriene). Ca și alte startup-uri, Snips folosește un sistem gamificat în care utilizatorii sunt clasați pe un clasament.
interesant pentru: Utilizați cazuri în care controlul calității poate fi aplicat cu ușurință
Exemple:
- DeepMind, Maluuba, AlchemyAPI și mulți alții (a se vedea aici)
- VocalIQ (folosit Turk mecanic pentru a preda programul său cum vorbesc oamenii)
- Snips (cere oamenilor să contribuie în mod liber de date pentru cercetare)
strategia # 4: User-in-the-loop
o strategie de crowdsourcing care merită propria categorie este user-in-the-loop.Această abordare implică proiectarea de produse care oferă stimulentele potrivite pentru utilizatori pentru a da date înapoi sistemului. Două exemple clasice de companii care au folosit această abordare pentru multe dintre produsele lor sunt Google(completare automată În căutare, Google Translate, filtre de spam etc.) și Facebook (utilizatorii care etichetează prietenii în fotografii). Utilizatorii nu știu adesea că oferă acestor companii date etichetate gratuit.
multe startup-uri din spațiul de învățare automată s-au inspirat din Google și Facebook prin crearea de produse cu un UX tolerant la erori care încurajează în mod explicit utilizatorii să corecteze erorile mașinii. Deosebit de notabile Arere și Duolingo (ambele fondate de Luis von Ahn). Alte exemple includ Unbabel, Wit.ai și Mapillary.
interesant pentru: startup-uri centrate pe consumator cu interacțiune constantă cu utilizatorul
Exemple:
- Unbabel (traducătorii comunității corectează traducerile generate automat)
- Wit.ai (tabloul de bord furnizat / API pentru utilizatori pentru a corecta erorile de traducere)
- Mapillary (utilizatorii pot corecta detectarea semnelor de trafic generate de mașină)
strategia # 5: Side business
o strategie care pare a fi deosebit de populară în rândul startup-urilor computer vision este de a oferi o aplicație mobilă gratuită, specifică domeniului, care vizează consumatorii. Clarifai, HyperVerge și Madbits (achiziționate de Twitter în 2014) au urmărit această strategie oferind aplicații foto care adună date suplimentare de imagine pentru activitatea lor principală.
această strategie nu este complet lipsită de riscuri (la urma urmei, costă timp și bani pentru a dezvolta și promova cu succes o aplicație). Startup-urile trebuie, de asemenea, să se asigure că creează un caz de utilizare suficient de puternic, care obligă utilizatorii să renunțe la datele lor, chiar dacă serviciul nu are beneficiile efectelor rețelei de date la început.
interesant pentru: întreprinderi start-up / platforme orizontale
Exemple:
- Clarifai (Forevery, fotografie descoperire app)
- HyperVerge (Argint, fotografie organizare app)
- Madbits (Momentsia, foto colaj app)